

Functional Data Engineering - A Blueprint
How to build a Recoverable & Reproducible data pipeline

The Rise of Data Modeling
Data modeling has been one of the hot topics in Data LinkedIn. Hadoop put forward the schema-on-read strategy that leads to the disruption of data modeling techniques as we know until then. We went through a full cycle that “schema-on-read” led to the infamous GIGO (Garbage In, Garbage Out) problem in data lakes, as noted in this What Happened To Hadoop retrospect.
The Data world Before Hadoop Era
We must walk through memory lane to understand why functional data engineering is critical. Let’s reference what the data world looked like before the Hadoop era.
Any blog is incomplete if it does not include a Gartner prediction, so let’s start with one. Garner predicted in 2005 around 50% of Data Warehouse projects would fail. Why is it so? Because the data warehouse is considered back office work, barely integrated with the product strategy. A simple addition of a column requires multiple approval workflows and a project.
The survey published by AgileData back in 2006 stat 66% of respondents indicated that development teams sometimes go around their data management (DM) groups. 36% of developers found the data group too slow to work with.
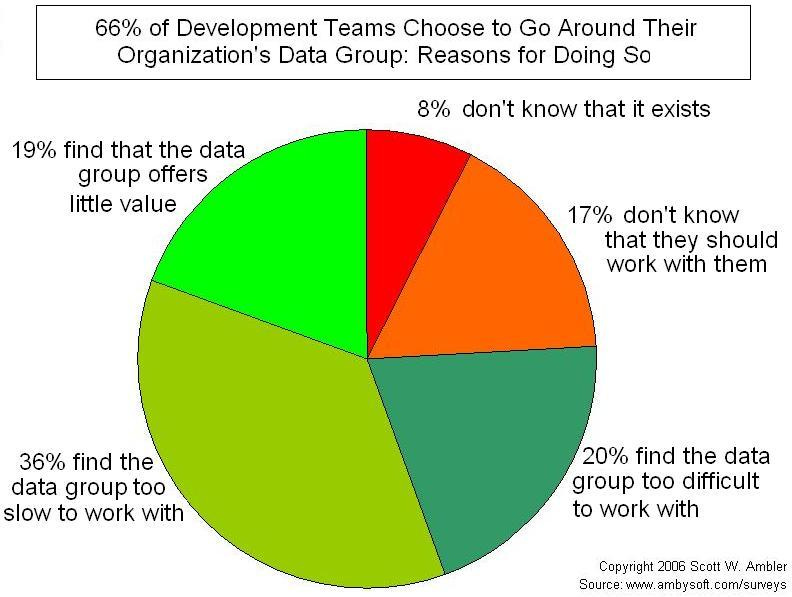
Source: http://agiledata.org/essays/culturalImpedanceMismatch.html [I know- pie chart 😃]
Growing Cultural Mismatch
Towards the end of 2010, we saw software engineering adopt devops principles and agile development methodologies. The “build fast, break things” era is reciprocal to "Let's have an architecture meeting to add a new column.” Once again, the Agile data blog captures the growing gap in the advancement of software engineering and how the data management gap increases the cultural mismatch.
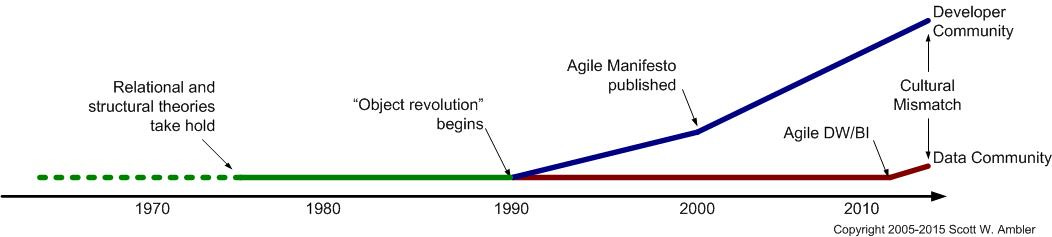
Source: http://agiledata.org/essays/culturalImpedanceMismatch.html
The cultural mismatch is largely still in play. Data is still struggling to find its feet in the organization, and articles like How to prove the value of your data team convince the leadership team.
The close we get to bringing the software engineering principles to data engineering, the greater we see the impact of data engineering in the industry.
Functional Data Engineering
Maxime Beauchemin wrote an influential article, Functional Data Engineering — a modern paradigm for batch data processing. It is a significant step to bring Software Engineering concepts into Data Engineering. The principle utilizes the advancement from Hadoop.
Cloud object storage like S3 makes the storage a commodity.
The separate Storage & Compute, so both can scale independently. Yes, human life is too short for scaling storage and computing simultaneously.
Functional data engineering follows two key principles
Reproducibility - Every task in the data pipeline should be deterministic and idempotent
Re-Computability - Business logic changes over time, and bugs happen. The data pipeline should be able to recompute the desired state.
How to Implement Functional Data Engineering?
In the article, Max writes about how the functional data engineering concepts drive the design principles of Apache Airflow. Let’s see how we can implement the principles in Lake House systems like Apache Hudi, Apache Iceberg & Delta Lake.
Schema Classification
The foundation of the implementation is the Schema classification. We can broadly classify the schema as
Entity - mutable data with a primary key. An Entity represents the business objects like the user, product, etc.,
Event - immutable data with a timestamp. An Event represents a business activity like user A added product X at timestamp Z into the shopping cart.
The founding principle of functional data engineering is everything is a time partition table. The time partition table maintains a full copy of the current state of an entity for each time partition.
Let’s take an example of a user entity table. A typical data modeling will look as follows.
CREATE TABLE dw.user (user_id BIGINT, user_name STRING, created_at DATE) PARTITION BY (ds STRING)
# ds = date timestamp of the snapshotA typical object storage file structure will look as follows. [Taking S3 as an example]
s3://dw/user/2022-12-20/<all users data at the time of snapshot>
s3://dw/user/2022-12-21/<all users data at the time of snapshot>The events, on the other hand, are immutable in nature and temporal in nature. A user_activity table will look as follows.
CREATE TABLE dw.user (user_id BIGINT, activity_type STRING, event_timestamp LONG) PARTITION BY (ds STRING, hour STRING)
# ds = date timestamp of the event
# hour = hour of the event [Assume the events are hourly pipeline]A typical object storage file structure will look as follows. [Taking S3 as an example]
s3://dw/user_activity/2022-12-20/10/<all users activity data for the hour 10 on 2022-12-20>
s3://dw/user/2022-12-20/11/<all users activity data for the hour 11 on 2022-12-20>Entity Modeling
Entity data pipelines can run in two modes.
Incremental Snapshot
Full Snapshot

Incremental Snapshot
We often don’t have the luxury of getting a full snapshot of an entity. A change data stream like CDC or event sourcing gives the incremental view of the entity as it is changing.
The incremental snapshot goes through an extra couple of pre-steps before taking the date-time table partitions.
Load the incremental data into a landing area with a date-time partition.
Merge the incremental snapshot into the base table. The base table is the initial bootstrap of a full table snapshot.
Full Snapshot
the full snapshot is a relatively simpler approach
Take the deep clone of the source data
Write a date time version table into the data warehouse
Why Latest View for Entity?
The date partition table streamlines the data pipeline process; at the same time, the entity's current state requires querying for ad-hoc analytics. Every time asking the end users to add a ds partition in the query filter will cause more confusion. A simple logical view on top of the latest partition greatly simplifies the accessibility.
CREATE OR REPLACE VIEW dw.user_latest AS
SELECT user_id, user_name, created_at, ds
FROM dw.user
WHERE
ds=<current DateTime partition>;Event Modeling
Events are append-only, removing the complication of merging or taking full snapshots of dimensions from the source.

Re-computability
One of the significant advantages of the functional data engineering paradigm, it requires less modeling upfront and enables time travel for both entities and events.
The data observability platform detected a data quality issue or a bug in pipeline computation? The functional data engineering pattern allows us to rerun from the interception of the bug to reproduce the data artifacts.
Let’s say the business wants to change the ARR (Annual Recurring Revenue) model? no problem. We can create an ARR_V2 [version 2] pipeline and recompute from the beginning of the date partition. It will instantly give the advantage of providing a historical view of changing business context.
The functional data engineering principles are not a replacement for any of the data modeling techniques. It makes sense to model your data mart for a domain such as Kimball or data vault. The functional data engineering principles allow us to recompute or re-generate the model if we get something wrong during the data modeling.
Conclusion
As Maxime Beauchemin quoted in another influential article The Downfall of the Data Engineer
Data engineering has missed the boat on the “devops movement” and rarely benefits from the sanity and peace of mind it provides to modern engineers. They didn’t miss the boat because they didn’t show up; they missed the boat because the ticket was too expensive for their cargo.
We barely started modernizing data engineering as we are seeing the increased adoption of the formal role of product managers in data. We have a long way to go, and I’m excited to see all the developments in the data engineering space.
If you want to discuss further functional principles in data engineering, Please DM me on LinkedIn or book a slot in my calendar.
https://www.linkedin.com/in/ananthdurai/
https://calendly.com/apackkildurai
Reference
Databricks: Merge operation in Databricks
https://docs.databricks.com/sql/language-manual/delta-merge-into.html
Apache Hudi: Upsert support in Apache Hudi
https://hudi.apache.org/docs/writing_data/
Apache Iceberg: Upsert support in Apache Iceberg
https://iceberg.apache.org/docs/latest/spark-writes/
Petrica Leuca: What is data versioning and 3 ways to implement it
https://blog.devgenius.io/what-is-data-versioning-and-3-ways-to-implement-it-4b6377bbdf93
Maxime Beauchemin: Functional Data Engineering — a modern paradigm for batch data processing
Maxime Beauchemin: The Rise of the Data Engineer
https://medium.com/free-code-camp/the-rise-of-the-data-engineer-91be18f1e603
Maxime Beauchemin: The Downfall of the Data Engineer
https://maximebeauchemin.medium.com/the-downfall-of-the-data-engineer-5bfb701e5d6b
All rights reserved ProtoGrowth Inc, India. Links are provided for informational purposes and do not imply endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Entity and Event seems like Dimension and Fact tables as popularized by Kimball and Ross?
This is an excellent overview of the key components of data modeling and functional data engineering, which will tie into data products/data contracts more and more, and the fundamental challenges with handling changes and late arrivals compiled into DE patterns.