
The Dark Data Tax: How Hoarding is Poisoning Your AI
Storage is cheap. Attention is finite. Hallucinations are expensive. It’s time to stop building Data Lakes and start managing Data Metabolism

With the increased adoption of the Lakehouses, we removed the last constraint on data accumulation.
We didn’t realize we were removing the last constraint on data obesity. The numbers are staggering. Enterprises now store 2.5 times more data than they did in 2019, yet the velocity of decisions derived from that data hasn’t just slowed—it has flatlined. According to IDC, global data storage capacity is estimated to reach 175 zettabytes by 2025, with 80% of that data unstructured. Furthermore, IDC predicts that 90% of unstructured data will remain unanalyzed.
This is data obesity: the condition where an organization accumulates data faster than it can derive value from it. It’s not a storage problem. It’s a metabolic one.
When Storage Became Infinite, Attention Became Finite
The obesity crisis began with the Lakehouse. Built on the triumvirate of S3, ADLS, and GCS, and crowned with Delta Lake, Iceberg, and Hudi, the Lakehouse solved data engineering’s oldest constraint: where to put the data. Object storage made retention elastic and nearly free. The cost of a gigabyte has fallen by 80% over the past decade, while enterprise data volume has grown by 250%.
However, the Lakehouse didn’t just lower costs—it removed the psychological barrier to data collection. When a terabyte costs less than a pizza, no one asks hard questions before ingesting. When schema evolution is automatic, there’s no migration friction to discourage table sprawl. When time travel promises infinite rollback, deletion feels like the destruction of potential value.
The result is a modern manifestation of Jevons’ Paradox: as storage became more efficient, our appetite for data expanded even more rapidly. We’ve built systems that can collect anything, but can’t measure whether that collection matters.
The Hidden Cost of Free Storage

Here’s what Lakehouse architecture diagrams don’t show: storage accounts for only 8% of the total cost of ownership. The remaining 92% is the human and computational effort to transform bytes into decisions—costs that scale with complexity, not volume.
This is the first symptom of data obesity: operational debt. Dark datasets don’t just sit there; they demand maintenance, schema migrations, and compliance audits. They clog your information schema, slow down your metastore, and multiply the blast radius of every infrastructure change.
The LLM Hunger Games: When Predators Can’t Hunt
Datology AI’s seminal research demonstrated that model performance doesn’t scale with dataset size—it scales with signal density.
Their experiments demonstrated that a curated 100TB corpus consistently outperformed a raw 1PB dataset, resulting in a 40% reduction in training time and a 35% reduction in inference costs. Redundant, inconsistent, or low-quality data not only slows training but also actively degrades performance through gradient noise.
Despite this evidence, enterprise adoption of LLMs has amplified data obesity rather than containing it. The prevailing architectural pattern—vectorizing entire document corpora and connecting models through RAG pipelines—assumes maximal data exposure is optimal. This leads to embedding every PDF, support ticket, and communication archive without evaluating the utility of the information.
The result is a predator that consumes indiscriminately but digests inefficiently. When an LLM retrieves three conflicting definitions of “active user” from dark, ungoverned partitions, the model doesn’t resolve the conflict—it synthesizes them into authoritative-sounding errors. The 68% of dark data that plagues analytics now introduces hallucination vectors into AI systems.
The Dark Data Tax: Internal Data Poisoning
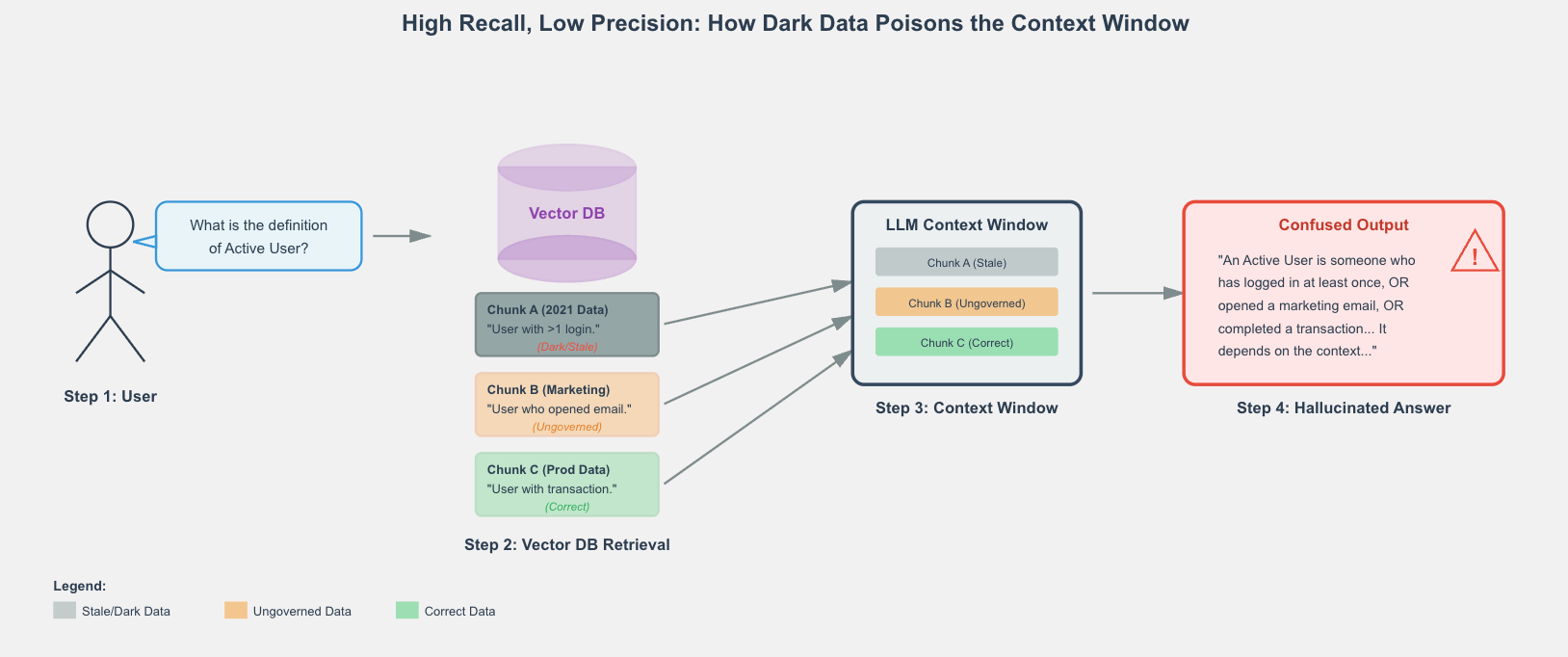
Consider the technical mechanics. An AI agent tasked with “analyzing customer churn” might query 200 tables across your Lakehouse, resulting in massive compute costs. But if 80% of those tables are dark—poorly documented, schema-drifted, or semantically redundant—the agent spends valuable inference cycles disambiguating rather than analyzing.
This is where the danger lies. Recent research on model robustness (such as findings from Anthropic) indicates that even a small fraction of incoherent data in the context window can disproportionately degrade output quality.
Dark data effectively acts as internal data poisoning:
Context Contamination: When an LLM retrieves three conflicting definitions of “active user”—one from a live table and two from dark, ungoverned tables—it lacks the context to discern the truth.
The Hallucination Vector: Instead of ignoring the noise, the model attempts to reconcile it, averaging the conflicting signals into authoritative-sounding nonsense.
This creates a severe form of cognitive debt. Dark data doesn’t just waste storage; it actively sabotages the insights derived from your good data. By introducing these “hallucination vectors,” you are effectively feeding your predator garbage, and the resulting insights are not just expensive—they are fundamentally compromised.
If data poisoning is the pathology of the individual model, we need a different framework to understand the collapse of the entire ecosystem. Ecology solved this problem a century ago.
The Predator-Prey Framework: Diagnosing Obesity
To transition from vague awareness to precise diagnosis, we require a model that captures how data systems become imbalanced. Ecology solved this problem a century ago.
In the 1920s, Alfred Lotka and Vito Volterra developed elegant equations that described predator-prey dynamics, explaining why ecosystems collapse when one species outnumbers the other. The model maps uncannily onto data systems:
Data Volume (x) = Prey. Reproduces through ingestion, replication, and instrumentation.
Data Value (y) = Predators. Analysts, models, and decision pipelines that rely on data to thrive.
The equations:
dx/dt = αx - βxy
dy/dt = δxy - γy
Where:
α = Prey growth rate (your ingestion velocity)
β = Predation rate (how easily analysts discover and query data)
δ = Conversion efficiency (how well analytics become decisions)
γ = Value decay (how quickly insights become stale)
The Emergence of Dark Data
Dark data isn’t just “unused data”—it’s the prey population that grows unchecked when predation fails to occur. In the equation dx/dt = αx - βxy, the term βxy represents data consumption and conversion into a value. When this term is too small relative to αx, the system experiences prey overpopulation.
Mathematically, dark data is the excess when:
αx >> βxy → dx/dt ≈ αx
In plain terms, your ingestion rate (α) is high, but your effective consumption rate (β) is low. The xy term depends on both available data (x) and active predators (y). When you have 10,000 tables but only 200 active analysts, even if each analyst works at maximum capacity, βxy cannot offset αx.
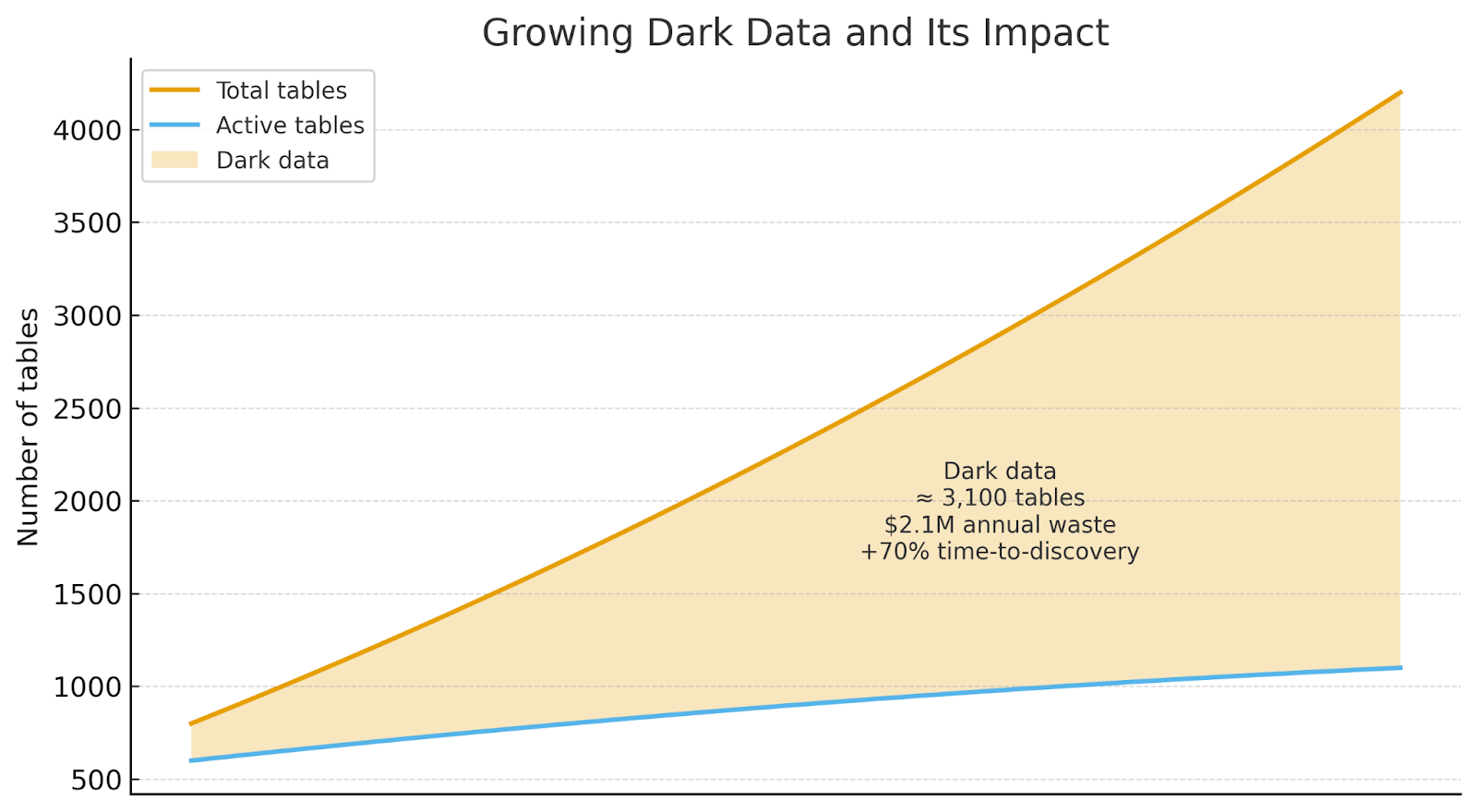
The Predator Starvation Crisis
The second equation, dy/dt = δxy - γy, predicts the consequence. When dark data grows, it doesn’t just increase x—it contaminates xy. The δ term (conversion efficiency) drops because analysts spend more time navigating noise. The γ term (value decay) increases because insights become obsolete more quickly in a chaotic environment.
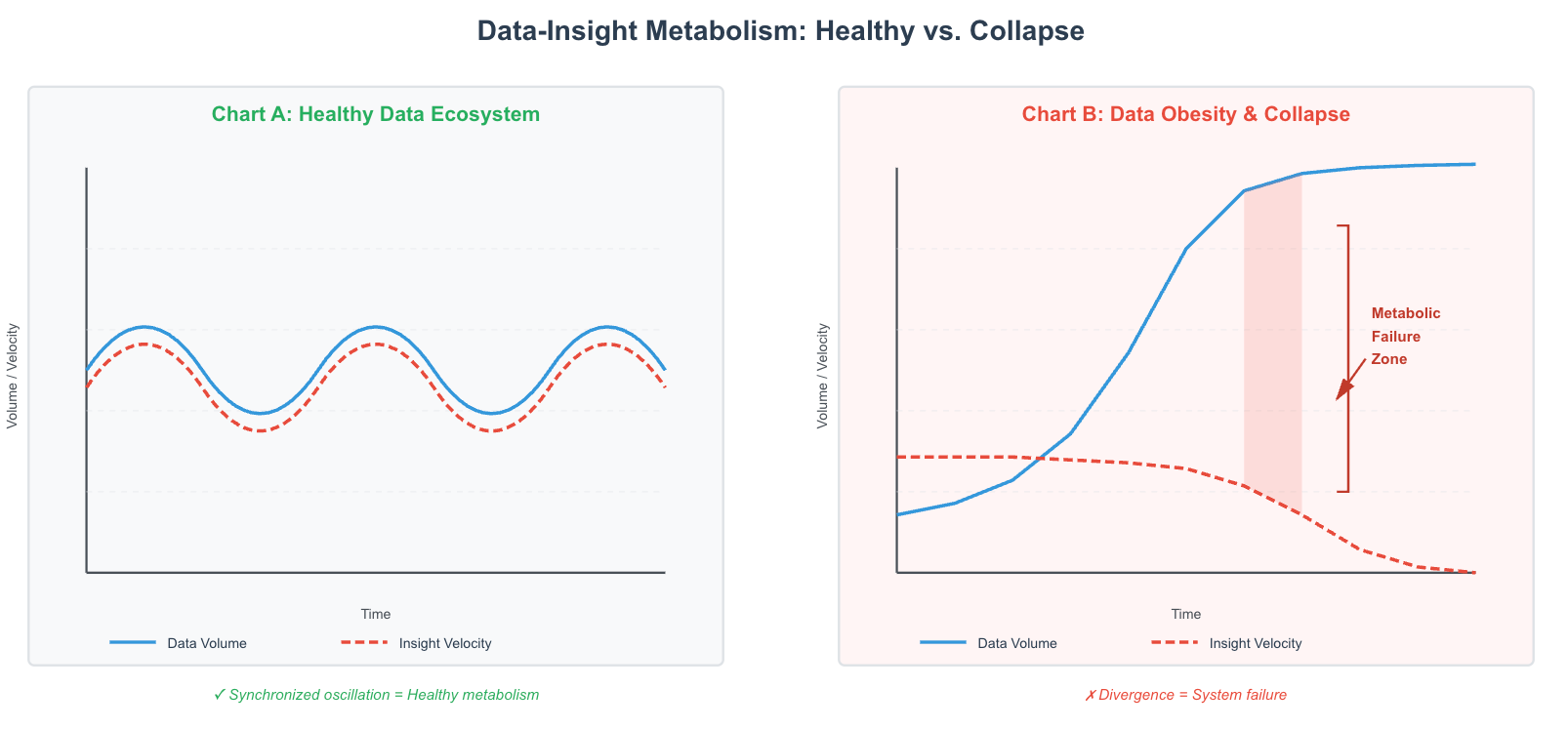
The result: dy/dt becomes negative—your organization’s ability to create value from data actually declines, even as you add more data.
This framework transforms dark data from a storage problem into an ecological pathology. Your data isn’t just unused—it’s overpopulated prey, starving your predators.
The Data Sustainability Index: Measuring Metabolic Health
If we use predator-prey dynamics to diagnose data obesity, we need a metric to measure its severity. We cannot manage what we do not measure.
The Data Sustainability Index (DSI) metric quantifies the metabolic efficiency of your data ecosystem—measuring how much energy (compute) your data generates relative to the weight (cost & complexity) it adds.
The Formula

To calculate this, we track three specific variables:
The Predator Activity: Total Analytical Compute Hours (TACH)
This measures consumption, not storage. It captures every SQL warehouse second, Spark job, BI refresh, and model training cycle.
Why it matters: TACH is a proxy for demand. Even a failed query or an inefficient scan counts as “positive” here because it signals that a predator is attempting to feed.
The Rule: If TACH = 0, the dataset is biologically dead.
The Environmental Drag: Lakehouse Total Cost
We must account for the full burden of the ecosystem.
The Calculation: Storage + Ingestion Compute + Governance Overhead.
The Hidden Tax: Don’t just count cloud credits. A dataset that costs $500/month to store but requires 5 hours of engineering maintenance carries a massive “cognitive weight” that must be factored in.
The Punishment Multiplier: Active Dataset Ratio
This is the most critical component. It penalizes hoarding.
Formula: (Datasets with TACH > 0) / (Total Datasets)
If you have 10,000 tables but only query 1,200 of them, your Active Ratio is 12%. This mathematically crushes your DSI score, reflecting the reality that the 8,800 dark tables are creating noise that makes it harder to find the 12% of valuable data.
The Scorecard: How Healthy Are You?
Once you calculate your DSI, the results typically fall into three zones:
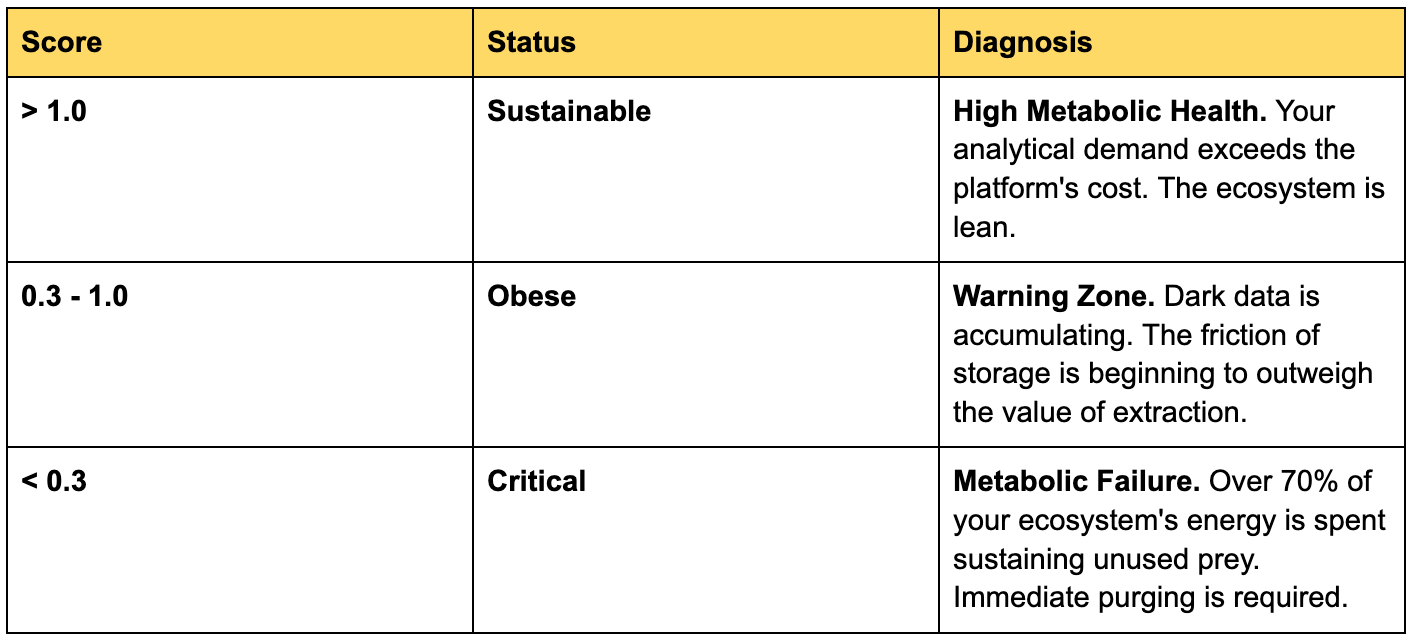
The Trajectory Warning: The absolute number matters less than the trend. If your DSI is declining month over month, it means your ingestion rate is outpacing your consumption rate. You aren’t scaling—you’re bloating.
Four Symptoms of Data Obesity
Dark data is the visible symptom of systemic metabolic failure. It manifests as four interlocking debts:
Operational Debt: The Cost of Unused Infrastructure
Unused datasets still demand pipeline maintenance, schema migrations, and dependency tracking. The obesity wasn’t just storage; it was engineering time diverted from value creation to waste management.
Cognitive Debt: The Tax on Every Decision
Analysts don’t just search for data—they sift through noise. When a data scientist needs “user_events” and finds 23 variations, the search cost becomes a tax on every decision. Studies in cognitive load theory show that decision quality degrades exponentially with choice overload. In obese ecosystems, analysts spend 40% of their time on data discovery and validation rather than analysis.
Compliance Risk: The Weight of Regulatory Exposure
GDPR and CCPA don’t care if you use personal data—only that you store it. A healthcare provider faced a $12M fine for retaining patient records in a “temporary” Lakehouse partition that had been dark for three years. Dark data is invisible to analytics but blindingly visible to auditors. Each unused dataset with PII is a latent liability.
Cultural Drift: The Normalization of Hoarding
Teams conflate “data-driven” with “data-hoarding.” Deleting a dataset feels riskier than keeping it because the cost of being wrong about deletion is visible (blame), while the cost of retention is invisible (slow decay). This creates a tragedy of the data commons, in which individual rationality produces collective dysfunction.
The Future: Autonomous Metabolic Management
As we instrument obesity metrics, we can automate weight management. Imagine a Data Obesity Controller:
Input Streams:
Real-time TACH telemetry
Decision attribution logs
Cost per table
Schema drift alerts
Control Actions:
Auto-archive dark datasets (reduce mass)
Suggest semantic model improvements (increase metabolism)
Alert on insight decay (prevent metabolic slowdown)
Recommend dataset deprecation (remove obesity)
This is the logical evolution of DataOps. We’ve spent a decade automating data production. The next decade belongs to automating data health.
Conclusion: The Healthiest Ecosystem is the Leanest
The obesity crisis teaches us a harsh truth: the organizations that thrive won’t be those with the largest lakes, but those with the highest metabolic rates.
The predator-prey framework gives us the language to diagnose this. The DSI gives us the metric to measure it. But the real work is cultural: we must stop celebrating data mass and start celebrating data muscle.
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.