
The Future of Data Engineering: DEW's 2025 Predictions
Emerging Innovations, Evolving Roles, and the Roadmap to Scalable AI-Driven Insights


DEW published The State of Data Engineering in 2024: Key Insights and Trends, highlighting the key advancements in the data space in 2024. We witnessed the explosive growth of Generative AI, the maturing of data governance practices, and a renewed focus on efficiency and real-time processing. But what does 2025 hold? After analyzing emerging patterns and vibrant conversations within the data community, DEW presents our top five predictions for the trends shaping the data world in the coming year.
1. Advancements in AI computing

NVIDIA is possibly once in a generation company to see the market cap as it becomes the largest company in the world in terms of its market cap. Google recently announced its breakthrough innovation in its quantum computing with Willow. AI-embedded PCs and devices with Neural Processing Units (NPUs) enable offline AI operations and improve data privacy. Meanwhile, innovations like Google’s Edge TPU will accelerate the shift toward energy-efficient edge computing, reducing dependency on centralized cloud infrastructures. Companies such as Amazon, Google, and Microsoft are intensifying competition in the custom AI chip market, with examples like Amazon’s Trainium2 chip showcasing a focus on specialized efficiency. These trends mark a decisive move towards hybrid and energy-efficient computing architectures, bridging the gap between performance, cost, and privacy in AI applications.
At the cutting edge, neuromorphic and quantum computing are improving significantly, opening new horizons for AI capabilities. Inspired by the human brain, Neuromorphic chips promise unparalleled energy efficiency and the ability to process unstructured data locally on devices. The advancement in computing will expand AI’s role in autonomous systems and robotics. Together, these advancements in AI hardware will power breakthroughs in natural language processing, computer vision, robotics, and healthcare in 2025 and beyond.
2. Domain-Specific & Specialized Language Models

Domain-specific language models (LLMs) will evolve the application of AI across industries. These models, trained on sector-specific datasets, will deliver unparalleled accuracy and relevance. Industries such as healthcare, finance, legal, and manufacturing will embrace these models to tackle complex, context-rich challenges with precision. By tailoring AI capabilities to meet the nuanced demands of individual sectors, domain-specific LLMs will pave the way for a new wave of innovation, transforming workflows and decision-making processes across the enterprise landscape.
Alongside the rise of domain language models, small language models (SLMs) will gain prominence for their cost-effectiveness and adaptability. Fine-tuned on task-specific datasets, SLMs will offer highly efficient solutions that often outperform their larger counterparts in focused applications. With reduced computational requirements and enhanced ease of deployment, SLMs will democratize access to AI, enabling organizations of all sizes to implement sophisticated language capabilities without the overhead of managing resource-intensive systems.
3. AI Orchestrators & Multistep Reasoning

As enterprises adopt a growing number of specialized AI agents, AI orchestrators will emerge as the backbone of the AI-native data stack. These orchestrators will serve as intelligent control planes, dynamically routing tasks to the most suitable agents, synthesizing their outputs, and recommending actionable insights. Equipped with deep content understanding, multilingual processing capabilities, and support for diverse data types, they will seamlessly integrate multiple AI agents into cohesive workflows.
Simultaneously, AI models will advance to tackle complex problems using multistep reasoning, a critical evolution beyond simple question-and-answer paradigms. These models will enhance their accurate and insightful analysis capacity by breaking intricate tasks into smaller, sequential steps. This capability will enable AI agents to perform long-tail automation jobs in coding, medicine, law, and other industries. Together, AI orchestrators and multistep reasoning will mark a new era in AI, amplifying its impact on problem-solving and decision-making across domains.
4. The New Age Data IDEs

The demand for data insights drives a fundamental shift in how organizations approach data engineering. In 2025, we will witness the rise of a new breed of integrated development environments (IDEs) specifically designed to democratize data access and manipulation effectively. Tools like lakebyte.ai are the beginning of such a revolution.
These New Age Data IDEs will be characterized by:
Seamless Integration: They will seamlessly integrate the entire data lifecycle, from data ingestion and transformation to analysis, visualization, and deployment, all within a unified environment.
AI-Powered Assistance: They will be infused with AI capabilities, offering intelligent code completion, automated data cleaning, and smart suggestions for pipeline optimization. Imagine an IDE that not only helps you write code but also understands the semantics of your data and can suggest the best way to transform it.
Low-Code/No-Code Interfaces: Visual, drag-and-drop interfaces will allow users with limited coding experience to build and manage data pipelines while still providing the flexibility for advanced users to write custom code when needed.
Collaboration Features: These IDEs will facilitate seamless collaboration between data engineers, data scientists, analysts, and business users, enabling them to work together on data projects within a shared environment.
Built-in Data Governance: Data quality checks, CI/ CD pipeline, the ability to run integration testing before pushing into production, access controls, and lineage tracking will be integrated directly into the development workflow, ensuring that data governance is not an afterthought.
Support for Multiple Data Sources and Formats: They will offer native connectors to a wide range of data sources, including databases, data lakes, streaming platforms, and cloud storage, and support various data formats, including structured, semi-structured, and unstructured data.
Cloud-Native and Scalable: These IDEs will be designed to run in the cloud, leveraging the scalability and elasticity of cloud infrastructure.
This democratization, facilitated by powerful and intuitive IDEs, will empower "Citizen Data Engineers"—individuals with domain expertise who may not be traditional programmers but can now build and manage data workflows. It will break down the barriers between technical and non-technical teams, accelerating data-driven innovation. In 2025, Prompt Wrangling will become the most important skill for data engineers.
5. The Emergence of LakeDB: LakeHouse Formats to DB

The lines between data lakes, data warehouses, and databases are blurring. In 2025, we predict the rise of a new paradigm: the LakeDB. This evolution of the LakeHouse concept will directly bring more robust database-like functionality to data lakes, combining the scalability and flexibility of object storage with the performance and ease of use of a traditional database. Critically, a true LakeDB will move beyond simply querying data on object storage & a table format; it will natively manage buffering, caching, indexes, and write operations, offering performance and efficiency currently found in LakeHouse.
Today's LakeHouses often rely on external processing frameworks like Spark or Flink for data ingestion, transformation, and write operations. It introduces complexity, latency, and interoperability issues with non-uniform performance across the implementations. LakeDBs will internalize these functions, providing:
Native Write Capabilities: LakeDBs will offer optimized write paths directly to the underlying object storage, eliminating the need for external processing engines for many common operations. The recent S3 conditional write indicates that the cloud object storage will support the LakeDB write path.
Intelligent Buffering and Caching: LakeDBs will intelligently manage data buffering and caching, optimizing for both read and write performance.
Built-in Transaction Management: LakeDBs will offer robust transaction management capabilities, leveraging technologies like S3 conditional writes and advanced metadata management to ensure data consistency and integrity.
Intelligent query performance: LakeDB improves query efficiency through advanced indexing, query optimization, and the integration of in-process OLAP engines like DuckDB, enabling small data processing to be more efficient. The users don’t need to build a query strategy for small data vs big data, where LakeDB picks the best possible strategy.
Automated data management features like data tiering, compaction, and other optimizations to simplify operations and reduce costs.
Support for Vector Search & Beyond: Built-in support for vector databases and similarity search. It will allow the pick and choose the indexing technique to apply in each column to optimize the write and read performance. The LakeHouse formats have already started this with Hudi’s secondary index support and Delta’s variant data type.
While the LakeDB concept is still nascent, we expect to see significant innovation in this space in 2025. The existing LakeHouse format may evolve to incorporate more LakeDB-like features, and new solutions built from the ground up with this vision may emerge.
6. Data Mesh & Contract Driven by Zero ETL and Federated Architectures
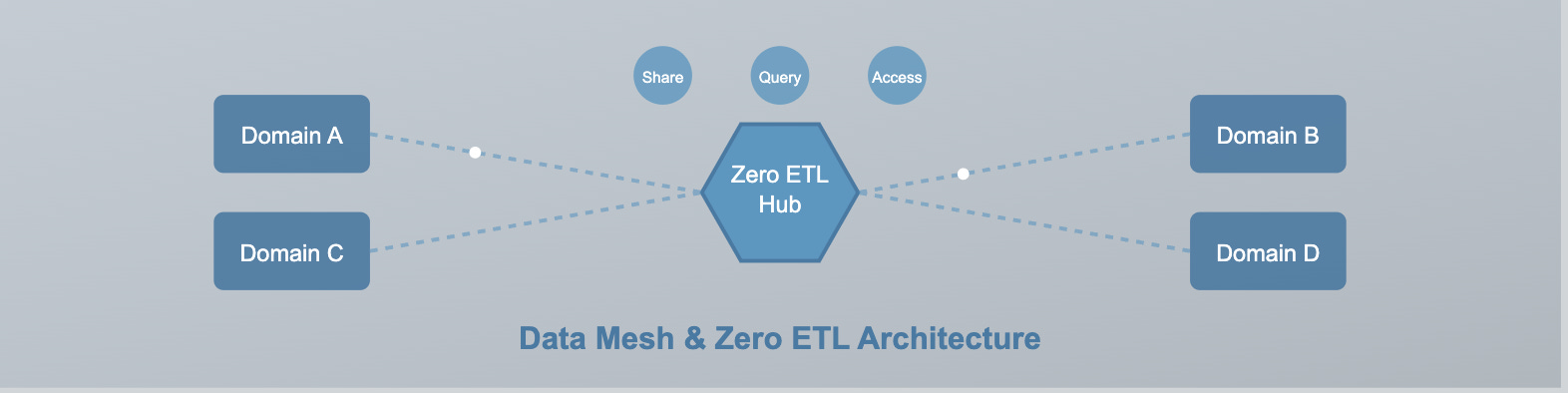
Though there is much skepticism about data contracts and mesh, given the trend, we predict that more companies will embrace data mesh architecture, especially for cases where intra-company data exchange is required. Zero ETL and federated query architectures mostly drive this shift.
Zero ETL represents the movement toward minimizing data movement and duplication. Technologies like data virtualization, federated query engines, and data-sharing protocols will enable organizations to access and analyze data in place without the need for complex and time-consuming ETL processes.
Data sharing will become a first-class concern. Secure and efficient data-sharing protocols and platforms will enable organizations to collaborate with partners, customers, and competitors, unlocking innovation and value-creation opportunities. Expect greater adoption of standards like Delta Sharing and continued evolution.
These trends, combined with the Data Mesh philosophy, will empower domain teams to own their data pipelines, create and manage data products, and share data seamlessly across organizational boundaries. Data sharing becomes critical as companies increase their adoption of training LLM with their data; the data sharing model will lead to greater agility, faster time to insight, and a more decentralized and scalable approach to data management.
Conclusion:
The rise of AI, the democratization of data through new IDEs, the evolution of the data engineer role, the emergence of LakeDB, and the mainstream adoption of Data Mesh principles fueled by Zero ETL and federated architectures will reshape the landscape, creating both exciting opportunities and new challenges. As we navigate this dynamic environment, one thing remains certain: the role of the data engineer has never been more critical. By embracing these trends and adapting to the evolving demands of the data-driven world, data engineers will continue to be the architects of insight, the guardians of data quality, and the driving force behind innovation. The future of data is bright, and we at Data Engineering Weekly are thrilled to be your guide on this exhilarating journey.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
Really interesting predictions, looking forward to what 2025 & beyond holds for the world of data.
Also, the variant datatype in delta & secondary indexes in hudi aren't directly related to vector database & similarity search in my understanding..!