
The Missing Interface in Data Platform Engineering
How data leaders should design the boundary between platforms and dependent teams.

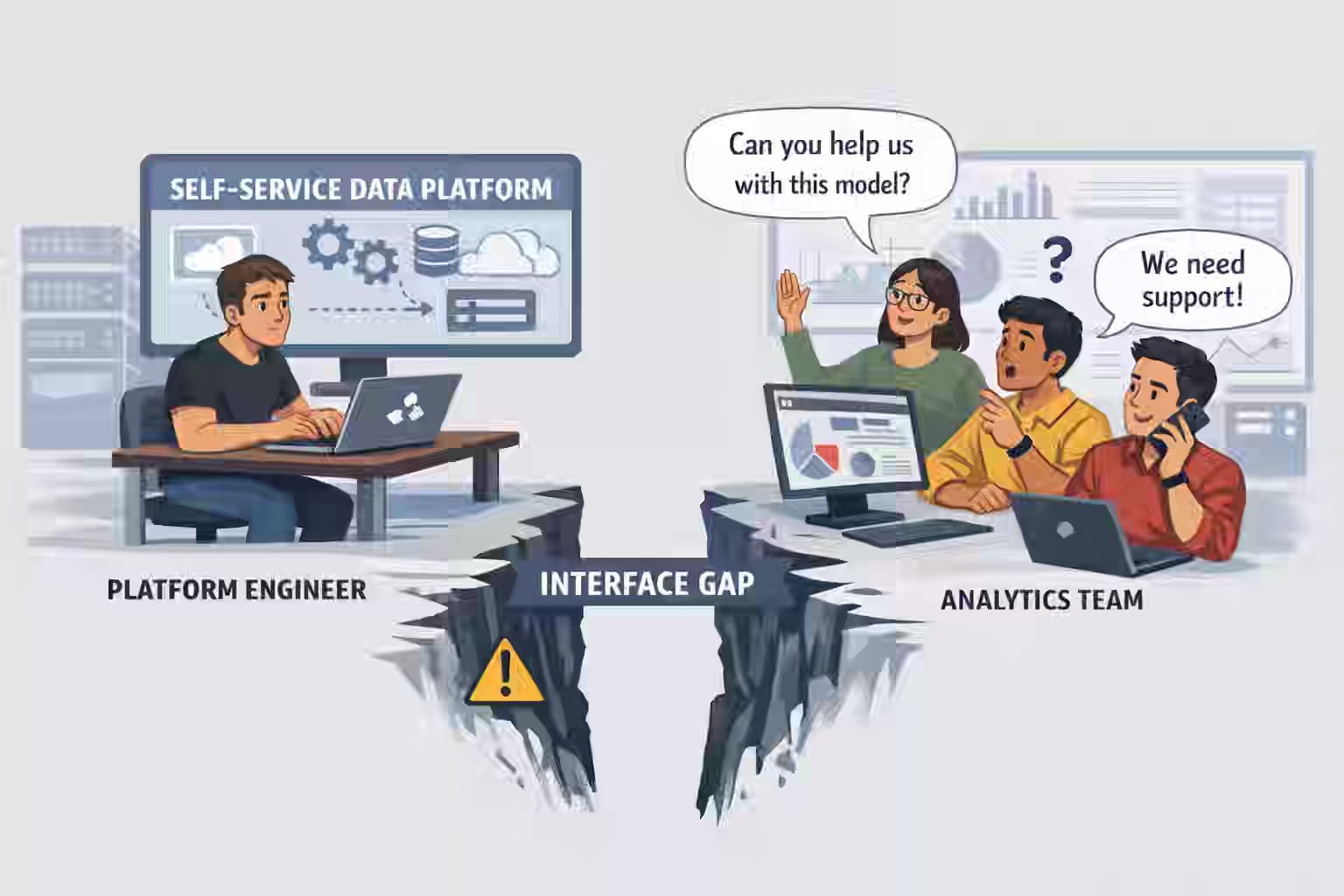
A familiar pattern plays out inside many platform organizations. A data platform team ships what it sees as a milestone: a self-service stack with governed datasets, reusable pipelines, access automation, lineage, templates, and documentation. Leadership sees leverage. The platform team sees scale.
Then requests start arriving.
Can someone help model the first few datasets? Can someone validate the ownership setup? Can someone walk us through the abstractions? Can the platform team handle the initial rollout for this one use case?
Platform teams often call that resistance to self-service. The real problem is simpler: the interface is incomplete.
The tooling exists. The technical path exists. But the consumer team still cannot tell where responsibility begins, where support ends, what failure looks like, or what the team must operate independently.
The platform team sees a reusable capability. The consumer team sees a system that still depends on human interpretation.
Both teams are acting rationally. The platform team has built a technical interface. The consumer team is still looking for an operating interface.
That gap accounts for more platform friction than most platform strategies acknowledge.
Data platform engineering often gets framed as a systems problem: storage layers, compute engines, orchestration, metadata, governance, access control, and developer tooling. Those components matter. Once a platform becomes shared infrastructure, however, the harder problem shifts. The platform becomes a dependency surface across teams, applications, workflows, and operational responsibilities.
At that point, the key question shifts from “What did we build?” to “How should other teams depend on it?”
That question defines the real interface in data platform engineering.
Data Platform Engineering is Coordination Engineering
A mature data platform is not just a collection of capabilities. A mature data platform creates a shared system that other teams must trust, integrate with, and operate against. Every dependency on that platform carries assumptions: what stays stable, what can change, who responds when something breaks, how fast a team can expect support, what a consumer must understand, and what remains the platform team’s responsibility.
Teams carry those assumptions whether they write them down or not. When teams leave them implicit, engineers reconstruct them through tickets, Slack threads, tribal knowledge, escalations, and repeated misunderstandings. When teams make them explicit, the assumptions become part of the platform’s operating interface.
The operating interface has two parts.
One part defines the explicit rules that govern the relationship: schemas, APIs, freshness guarantees, ownership boundaries, compatibility expectations, escalation paths, and adoption responsibilities.
The other part defines the communication pattern through which teams use those rules: reactive ticketing, temporary embedding, joint execution, self-service federation, or community contribution.
Most platform failures begin when teams underdesign one or both parts.
The platform team thinks it has published a reusable capability. The consumer team experiences an ambiguous boundary. We could document the schema, but not the operational expectations. The self-service path may exist, but the adoption model does not. The API may be stable, but teams still negotiate failure semantics socially every time they matter.
Platform maturity, then, depends on more than better tooling. Platform maturity depends on how well teams design the dependency boundary between the platform and the groups that rely on it.
A contract is only one layer of the operating interface
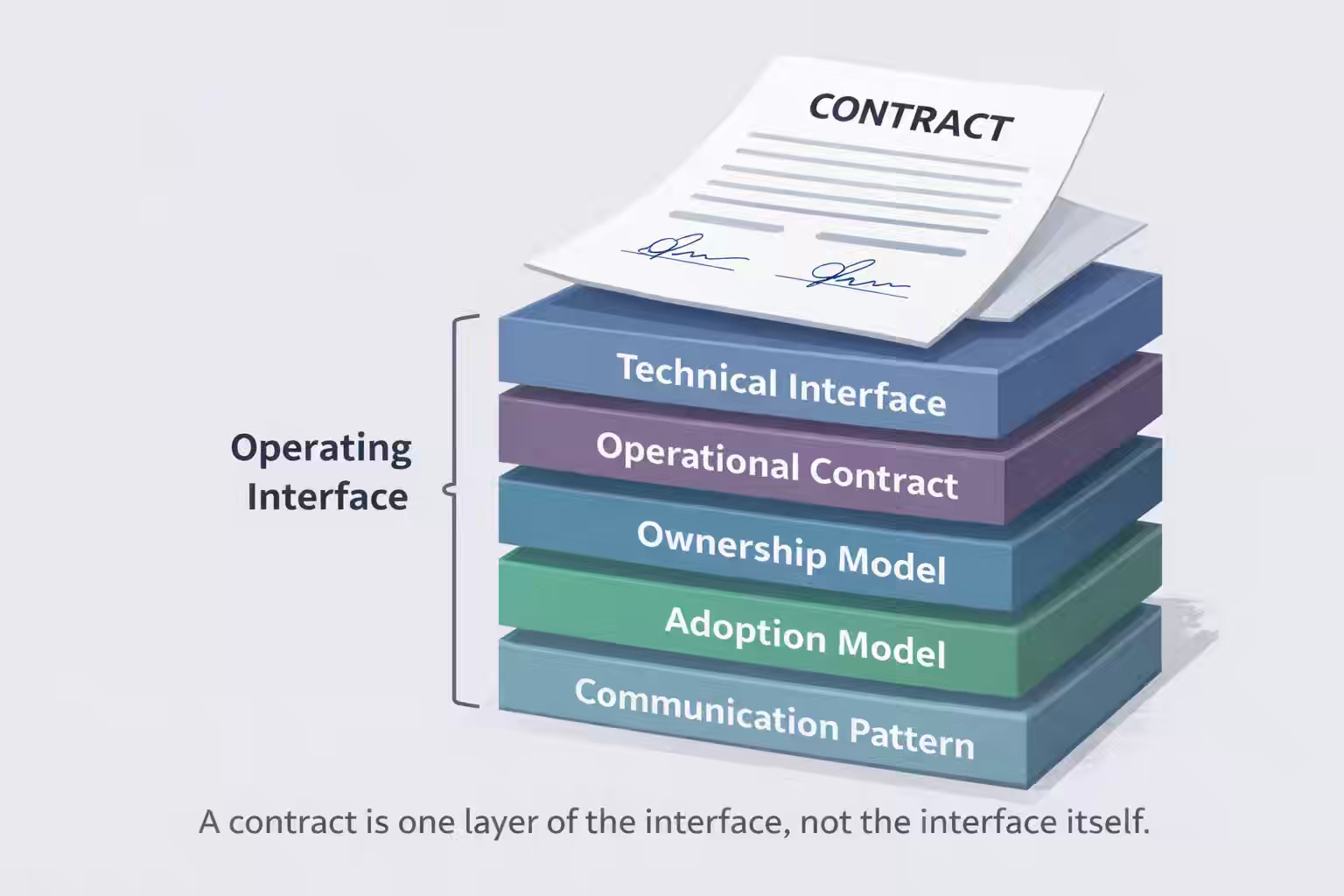
Platform discussions often stall because engineers use the word contract too narrowly. In data work, many engineers hear “contract” and immediately think of a data contract: schema shape, field semantics, compatibility rules between producer and consumer, and perhaps a validation mechanism.
That category matters. That category does not cover the problem.
A stack of interface layers governs a data platform dependency, and each layer answers a different question.
1. Technical interface
The technical interface is the layer most teams already know how to discuss. It includes APIs, schemas, tables, events, payloads, SDKs, versioning rules, authentication mechanisms, and compatibility expectations. The technical interface defines the shape of interaction.
When people say a platform has a clear interface, they often mean only that layer.
Teams can still fail operationally even when the technical interface is clear.
2. Operational contract
The operational contract defines runtime expectations. How fresh should the data be? What latency matters for a given workflow? How should retries behave? What happens when a dependency degrades? Which failures does the platform absorb, and which failures propagate to consumers? Which SLOs, error budgets, or maintenance windows apply?
The operational contract separates descriptive interoperability from dependable interoperability.
Two teams may agree on a schema and still disagree completely on whether a six-hour delay is acceptable, whether we tolerate the stale reads, or whether a breaking change in behavior requires a coordinated rollout.
3. Ownership model
The ownership model defines authority and accountability. Who approves interface changes? Who owns backward compatibility? Who responds during incidents? Who decides when a consumer must migrate? Who can reject a new use case because it violates platform constraints?
Many recurring platform conflicts are ownership failures disguised as technical disputes.
A consumer team says, “The platform changed under us.” The platform team says, “You were never supposed to rely on that behavior.” In most cases, unclear ownership boundaries create the conflict long before the disagreement surfaces.
4. Adoption model
The adoption model defines what a consuming team must do to use the platform successfully. Is the platform truly self-service? Does first adoption require embedding? Must the consumer own pipeline logic, operational monitoring, data quality checks, and incident response? How much platform literacy must a team build before independence becomes realistic?
Most platform design documents ignore that layer even though it often determines whether adoption succeeds.
A workflow is not self-service because a platform engineer no longer types the commands. Self-service begins when a consumer team can understand, operate, and recover within the platform’s boundaries independently.
5. Communication pattern
Every platform also has a practical communication mode. Teams may collaborate through tickets, pairing, embedded work, shared planning, interfaces, or contribution models. Those patterns are not secondary to the platform. Those patterns determine how the platform behaves in practice.
When teams do not consciously design that layer, habits and local workarounds define it by default.
Together, those layers form the platform’s operating interface: the real boundary through which teams depend on one another.
Every Platform Already has a Communication Model
Platform teams often speak as though better tooling will eventually eliminate communication. Tooling never eliminates communication. Tooling only changes its shape.
A ticket queue is a communication system. An embedding is a communication system. An API with onboarding guides and escalation rules is a communication system. An internal RFC process also serves as a communication system.
For that reason, a platform maturity model is also a communication maturity model. The model describes not only what the platform team has built, but also how dependency information moves between the platform and its consumers.
Communication may remain human-mediated, partially codified, or increasingly interface-led. No single mode is always superior. The right mode depends on the capability’s maturity, the consumer’s readiness, and the complexity of the work.
Five ways platform teams and dependent teams actually work
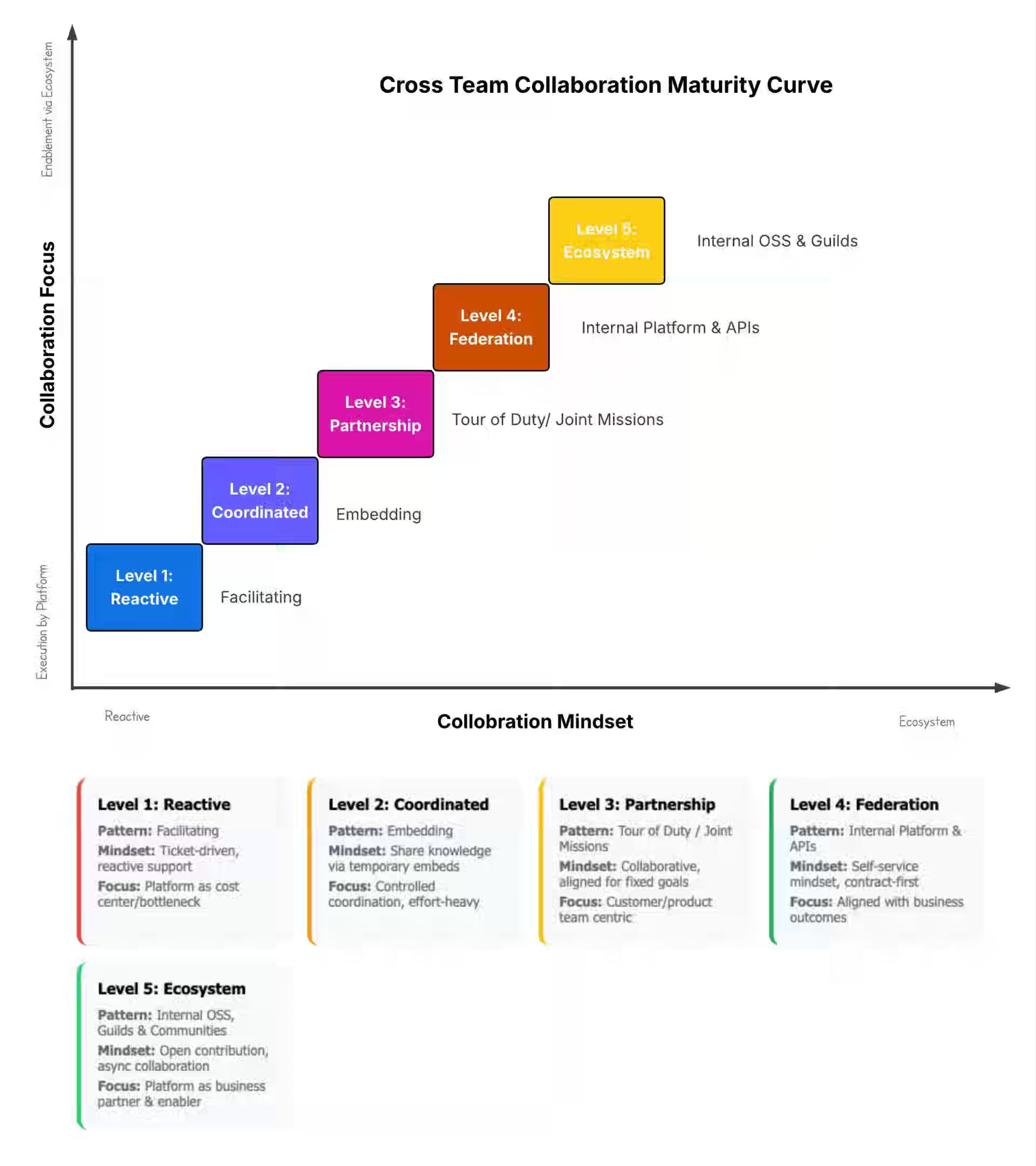
No single collaboration pattern fits every internal platform. The right mode depends on the capability in question, the consuming team, and the type of dependency with them. Strong platform organizations usually operate across several modes at once.
Teams rarely fail because they sit at the “wrong” level. Teams fail because they assume every consumer can interact with the platform through the same interface, when reality clearly shows otherwise.
Level 1: Reactive — The service desk
At Level 1, the platform team operates primarily through request fulfillment. Teams file tickets. Platform engineers provision resources, troubleshoot access, define ingestion patterns, or implement parts of the first workflow manually—knowledge about how the platform works lives mostly in people’s heads.
Many people dismiss that mode as immaturity. That judgment misses the point. Level 1 is where many new platform capabilities should begin.
When a capability is still emerging, the platform team does not yet know what the stable interface ought to be. Manual repetition helps the team discover the pattern worth codifying. The first few onboarding efforts reveal which inputs remain stable, which edge cases arise frequently, which assumptions break under real-world workloads, and which abstractions are premature.
The real danger is not Level 1 itself. The real danger is staying there after repetition becomes obvious.
Level 1 fails when demand scales linearly. Every new consumer increases direct demand on the platform team. The team becomes a fulfillment bottleneck. Consumers experience the platform as a queue instead of a leverage point. Platform engineers spend more time context-switching than building reusable capabilities.
Teams should move beyond Level 1 when repetition becomes predictable. Once the same task repeats enough times to reveal a stable pattern, some part of the operating interface should move out of people’s heads and into a reusable form.
Level 2: Coordinated — The embedding
At Level 2, the platform team transfers capability through direct collaboration. A platform engineer temporarily works with a consumer team to bootstrap adoption, interpret abstractions, and help the team operate inside the intended boundary.
Level 2 is not just support. Level 2 is a deliberate adoption model.
Embedding works when the platform capability is ready enough to be reused but still requires high-context interpretation. Embedding also works when the platform team needs to learn from consumers before it can fully stabilize the interface. The interaction runs in both directions: the platform teaches the intended path, and the consumer exposes where the path is incomplete.
Level 2 fails when dependency persists. The embedded engineer becomes the permanent translator. The team learns to route every ambiguity to a familiar person rather than building independent platform fluency. Once the embedding ends, the team slides back into ticketing.
Teams should move beyond Level 2 when understanding becomes repeatable. Once the same questions keep recurring, lack of exposure is no longer the main problem. Interface clarity is the problem. The platform then needs better runbooks, better failure handling, clearer ownership boundaries, or a more legible self-service path.
Level 3: Partnership — The joint mission
At Level 3, platform and consumer teams align around a shared objective for a bounded period. Level 3 is not request fulfillment, nor is it simple enablement. Level 3 is a temporary joint execution model.
Level 3 works when the dependency boundary itself is part of the problem. Teams often need Level 3 when they launch a new real-time product feature that requires changes across ingestion, serving, governance, and application behavior; when they stand up an experimentation platform that affects both platform architecture and domain logic; or when they build a new cross-cutting data product whose responsibilities cannot yet be separated cleanly.
Level 3 creates speed under complexity. Instead of negotiating everything through a queue, the teams create a shared execution context.
Level 3 fails when the temporary mission becomes a permanent entanglement. What was supposed to be a time-boxed collaboration becomes a staffing model. The platform roadmap drifts toward one team’s local priorities. The consumer team stops building independent ownership.
Teams should move beyond Level 3 when reusable patterns emerge. Once joint work starts producing structures that other teams will need, the organization should ask which parts belong in a generalized operating interface rather than in a persistent bespoke relationship.
Level 4: Federation — The self-service operating interface
At Level 4, teams collaborate primarily through explicit interfaces rather than constant human mediation. The platform publishes technical interfaces, operational expectations, ownership rules, onboarding guidance, and support boundaries clearly enough that consuming teams can adopt capabilities independently.
Level 4 is where platform economics start to work.
The marginal cost of onboarding new teams drops because the interface does more of the teaching. The platform team shifts away from request fulfillment and toward maintaining compatibility, reliability, documentation, tooling, and interface evolution.
Many organizations fool themselves at Level 4.
A team can publish an API, a portal, or a template and claim self-service while leaving the actual operating interface incomplete. The consumer can create the resource, but does not know how to handle failure. The documentation describes the happy path, but not the migration path. The schema is versioned, but the escalation model is still social. The ownership boundary exists in theory, but not in behavior.
That condition is not federation. That condition is a ticket queue with better branding.
Level 4 fails when self-service arrives too early. The platform exposes an interface before it has done enough repeated work to understand which parts are stable and which parts still require human judgment. Consumers adopt the easy 60% and escalate the hard 40%, forcing the platform team to run Level 1 and Level 4 simultaneously.
A healthy Level 4 shows more than usage. A healthy Level 4 shows independent operation. A consuming team should be able to adopt the capability, reason about normal failure, understand the support model, and make routine changes without renegotiating the relationship each time.
Level 5: Ecosystem — The internal commons
At Level 5, teams not only consume the platform. Teams extend it. The platform becomes a stewarded commons with contribution pathways, governance, standards, RFCs, and shared maintenance expectations.
That operating model looks attractive in strategy decks because it suggests scale through internal open-source behavior. In practice, organizations struggle to sustain it.
Contribution requires more than technical maturity. Contribution requires governance maturity. Teams need clarity on how to adopt the contribution, how to review its quality, who maintains the artifact over time, how support obligations are assigned, and how the platform distinguishes production-grade extensions from abandoned experiments.
Level 5 fails when the commons turns into unmanaged sprawl. Shared repositories fill with unevenly maintained components. The boundary between the core platform and the contributed surface becomes blurry. Consumers cannot distinguish between governed and incidental capabilities.
For many organizations, Level 4 is the durable steady state. Level 5 becomes valuable only when culture, incentives, and governance can support shared stewardship.
The missing variable is contract literacy
Most discussions of platform maturity focus on the platform side. That view is incomplete.
A platform can be highly mature in its own design and still fail in practice because the consuming team is not ready to operate against that interface. A Level 4 platform paired with a Level 1 consumer often behaves like a Level 1 system.
Consumer readiness matters, but teams should define the term more precisely than “platform familiarity” alone.
Consumer readiness is really a form of contract literacy. Consumer readiness measures a team’s ability to understand the operating interface, interpret the support boundaries, reason about failure modes, absorb ownership, and use the self-service path without relying on informal rescue.
A mature platform with a new team often needs Level 2 interaction first. The capability may be stable, but the team lacks the context to operate within it.
An early platform with a strong consumer base may benefit from a Level 3 partnership. The capability is yet to enter production, but the team is strong enough to co-develop the future interface.
A mature platform with a mature consumer can operate effectively through Level 4 and, in some cases, Level 5.
An early platform with a new consumer should not pretend to be anything other than Level 1 for a while.
The diagnostic question is not “How mature is the platform?” The better question is, “How mature is the dependency relationship, given both sides of the interface?”
Why platforms fail even when the interface exists
Many platform incidents seem surprising only when the platform team mistakes the technical interface for the whole interface.
A schema can remain stable even as the operational contract breaks down. A consumer receives the expected fields but cannot tolerate the freshness lag introduced by the new implementation.
An API can be correct while the ownership model remains unclear. Both teams assume the other team is responsible for migration sequencing, and the rollout fails in the gap.
A portal can be self-service while the adoption model remains incomplete. The consumer can provision the resource, but does not know which observability, alerting, backfill policy, or quality checks now belong to the team.
Documentation can be extensive while the communication pattern remains reactive. The written material explains the happy path, but the only reliable way to get edge-case answers is still to message a platform engineer directly.
Each example points to the same problem. The platform appears mature on paper and unstable in practice because one layer of the operating interface is missing.
That pattern also explains why many arguments about “data contracts” feel unsatisfying. A schema contract may remove one class of ambiguity while leaving the dependency relationship fundamentally underdesigned. Platforms do not scale on descriptive clarity alone. Platforms scale when the operating interface becomes explicit enough for teams to coordinate predictably.
Why does this matter more in an agentic enterprise
As organizations move toward AI-mediated operations, autonomous workflows, and increasingly automated decision loops, the cost of implicit interfaces rises sharply.
Human teams can absorb ambiguity through judgment, relationships, escalation habits, and informal context. Human teams can often compensate for missing rules because they know whom to ask, which unwritten assumptions are in place, and when a local exception is acceptable.
Automated systems do not compensate in the same way. Automated systems require explicit state, explicit boundaries, and explicit expectations. A platform boundary that depends on tribal knowledge, undocumented ownership, or socially negotiated failure handling already strains human teams. That same boundary becomes structurally limiting when an organization wants automation to operate consistently across it.
No company needs a grand operating model of the enterprise to benefit from that insight. Organizations do need a simpler discipline. Teams need to make the dependency interface between systems and teams legible enough to operate without constant interpretation.
Maturity is reversible
We view the maturity models as a ladder. Real organizations behave more like shifting systems.
A platform that reached Level 4 can slide back toward Level 1 when documentation rots, examples stop working, and teams stop trusting the interface. An embedding that once worked can decay when the engineers who learned the system leave, and the knowledge never becomes fully externalized. A clear ownership model can collapse after a reorganization. A rearchitecture can reset operational assumptions so thoroughly that teams must return to manual coordination until the new boundary stabilizes.
Those events are not unusual. Those events are the normal dynamics of organizational life.
A maturity model is useful not because it promises to eliminate regression. A maturity model is useful because it helps teams name regression quickly and respond deliberately.
If a self-service platform has quietly reverted to a ticket queue, the problem is not just support volume. Some part of the operating interface has decayed: the technical surface, the operational contract, the ownership model, the adoption model, or the communication pattern.
Once teams name that decay, they can turn frustration back into design work.
The real platform interface is organizational.
The hardest part of a data platform is rarely the infrastructure itself. The hardest part is designing the boundary between the platform and the teams that depend on it.
That boundary cannot be reduced to schemas or APIs alone. The boundary includes operational expectations, support models, ownership rules, adoption assumptions, and the communication pattern through which those expectations become real.
When teams leave those layers implicit, they do not avoid design work. They push the work into tickets, escalations, workarounds, and repeated misunderstandings. When teams make those layers explicit, the platform becomes easier to trust, adopt, and scale.
Data platform engineering is not just infrastructure engineering. Data platform engineering is interface design at the level of teams, systems, and responsibilities.
A maturity model should not rank organizations morally or insist that every platform must reach some final stage. A maturity model should give teams a vocabulary for the dependency relationships they actually have, the interfaces they are really exposing, and the ones they need to design next.
The missing interface in data platform engineering is not another layer of tooling. The missing interface is the operating interface that defines how dependent teams rely on one another.
Until teams make that interface explicit, most platform scale remains performative.
Once teams make that interface explicit, platform scale becomes real.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Excellent vocabulary.
This becomes even more pronounced when platform is operating like a two-sided marketplace. For example platform enabling cross polination of company products. For anything dependent on AI and statistically controlled - platform investments are a must.
This is really nice, aligns well with my experience. Never went above level 3 though.