
The Missing Layer in Your AI Stack: Context, Not Just State
From SQL to Semantics: The Rise of the Context Graph for AI Agents


Join The Great Data Debate to get answers to questions the data & AI industry is so curious about right now:
Where does context materialize in practice?
Semantic layers, ontologies, context graphs - what should data teams build in 2026?
Who owns context as meaning evolves?
Where should that context live: in the warehouse, inside agents, or in a dedicated context layer?
Why Data Engineers Must Think in Graphs, Not Just Tables
If you have been following the “Systems of Record” debate on tech Twitter, you likely saw the clash between the “Agents kill SaaS” camp and the “Long live the Database” camp. But for data engineers, the reality is more nuanced—and far more interesting.
As we move from dashboards to autonomous agents, we are hitting a wall. It turns out that knowing the state (what happened) is not the same as knowing the reasoning (why it happened).
Drawing on recent insights from Foundation Capital, Jamin Ball (Altimeter), OpenAI’s internal engineering team, and the TrustGraph manifesto, this post explores the emergence of the Context Graph. This missing architectural layer will likely redefine how we build data platforms in the agentic era.
The Problem: State Machines vs. Decision Traces
For the past decade, our role as data engineers has been to centralize data in the warehouse (or Lakehouse). We built ETL pipelines to move data from Salesforce, NetSuite, and Zendesk into a “Single Source of Truth.”
However, traditional Systems of Record (SoR) effectively act as “state machines.” They record the final output: the organization closed a deal, applied a discount, and escalated a ticket. But they fail to capture the decision traces.
As Foundation Capital notes, the reasoning behind a decision—the Slack threads, the cross-system synthesis, the VP’s verbal override of a policy—is rarely captured in the database. A CRM might show a “20% discount,” but it won’t tell an AI agent why that exception was granted (e.g., “Customer represents a strategic entry into the APAC market”).
Without these traces, agents fly blind. They have the rules (”Do not give discounts >10%”), but they lack historical context on when and why they were violated.
The Solution: The Truth Registry and the Context Graph
To address this, we observe a bifurcation in the modern data stack, as illustrated by the Hybrid Agentic Architecture (see Figure 1 below).
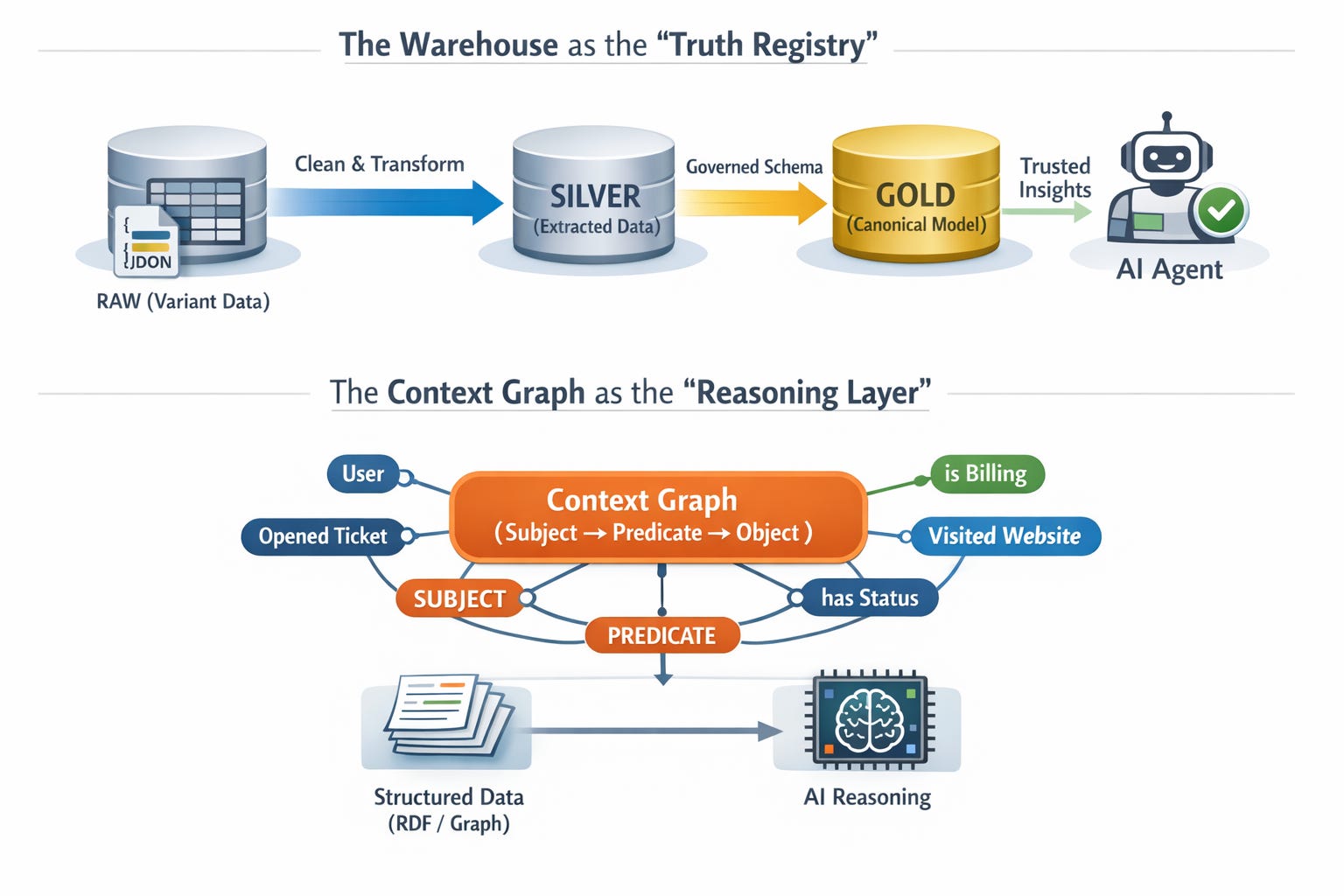
This architecture consists of two distinct but integrated planes:
1. The Warehouse as the “Truth Registry.”
Jamin Ball argues that systems of record aren’t dying; they are becoming “boring, rock-solid sources of truth”. In an agentic world, the warehouse must evolve into a “Truth Registry” that encodes semantic contracts.
Agents are fragile. If an agent hallucinates the definition of “Churn,” it can automate disastrous decisions. Therefore, we must clean and canonize data before the agent sees it. In the architecture above, the flow is from Raw (Variant) to Silver (Extracted) to Gold (Canonical Model).
Engineering Takeaway: You cannot feed agents raw JSON blobs. Extracting variant columns into typed, named columns in the Silver layer is critical. It transforms “available data” into “governed data,” preventing agents from guessing schemas at runtime.
2. The Context Graph as the “Reasoning Layer.”
While the warehouse handles facts, the Context Graph handles relationships. TrustGraph defines a context graph as a “triples-representation of data (Subject → Predicate → Object) optimized for AI”.
Why a graph? Because structure is information. When you feed an LLM structured data (like RDF or Cypher), the structure itself encodes meaning. This allows agents to traverse relationships that SQL joins struggle to represent—stitching together a user’s support ticket, their billing status, and their web activity into a single, queryable context.
Case Study: Inside OpenAI’s Data Agent
OpenAI recently reported that standard metadata was insufficient for their internal data agent. They had to build a custom “Context Layer” that closely resembles the architecture above.
Their agent failed when it relied solely on table schemas. To fix this, they added:
Human Annotations: Curated descriptions of what tables actually mean (e.g., “This table excludes logged-out users”).
Code Enrichment: They used “Codex” to crawl their own codebase, understanding data lineage not just by metadata, but by reading the pipelines that produced the data.
This confirms a major trend: The metadata is the model. Providing agents with a semantic ontology (machine-readable definitions of terms) is just as important as the data itself.
The “Front Door” is Moving
The implications for the industry are massive. Historically, if you owned the System of Record (like Salesforce), you owned the “Front Door” (the UI).
But as agents take over workflows, the UI is unbundling from the data. Jamin Ball compares this to the travel industry: GDS systems (Sabre, Amadeus) remained the backend source of truth, but Online Travel Agencies (Expedia, Booking) captured the front door—and the value.
In our new stack, the Agents become the OTAs. They are the new interface. The Warehouse/Lakehouse becomes the GDS—the invisible, essential infrastructure layer.
What This Means for Data Engineers
Stop Hoarding State, Start capturing Traces: We need to instrument our systems to emit “decision traces” on every run. If an agent (or human) makes a decision, record the inputs and the logic used, not just the result.
The Rise of the “Gold” Layer: Your dbt models are no longer just for dashboards. They are the safety rails for autonomous agents. Strict typing, “Gold” tables, and canonical definitions are non-negotiable.
Graph Literacy: You don’t need to be a Neo4j expert, but understanding the basics of triples (Subject-Predicate-Object) and ontologies is becoming a core DE skill.
Extract Your Semi-Structured/Unstructured Data: As shown in the architecture diagram, leaving data in unstructured blobs is a liability. Agents need explicit structure to reason safely.
As agents grow more capable, the infrastructure beneath them must evolve. The Context Graph offers a powerful new foundation—not just for smarter agents, but for more transparent, explainable, and aligned systems. It’s time for data teams to build not just pipelines, but reasoning engines.
References
https://x.com/KirkMarple/status/2003944353342149021
https://x.com/KirkMarple/status/2005443843848856047
https://foundationcapital.com/context-graphs-ais-trillion-dollar-opportunity/

Am I the only one in this world, who is not a fan of the medallion architecture?