
Towards Composable Data Infrastructure
A Case for Federated Data Catalog

The last few years have been an interesting journey for the data infrastructure landscape. The rapid growth of AI has sparked attention from the modern data stack, and we have declared that big data is dead, and so is the modern data stack. We quickly move on to the debate about table formats, the great data table format war, and the catalog war.
Though these debates seem like a hype cycle, we can’t deny these technologies' advancement in data engineering. As it is evident that a clean, contextual, and scalable data infrastructure is an essential ingredient for an organization to succeed in the AI era, we see increased focus on building better, scalable data infrastructure.
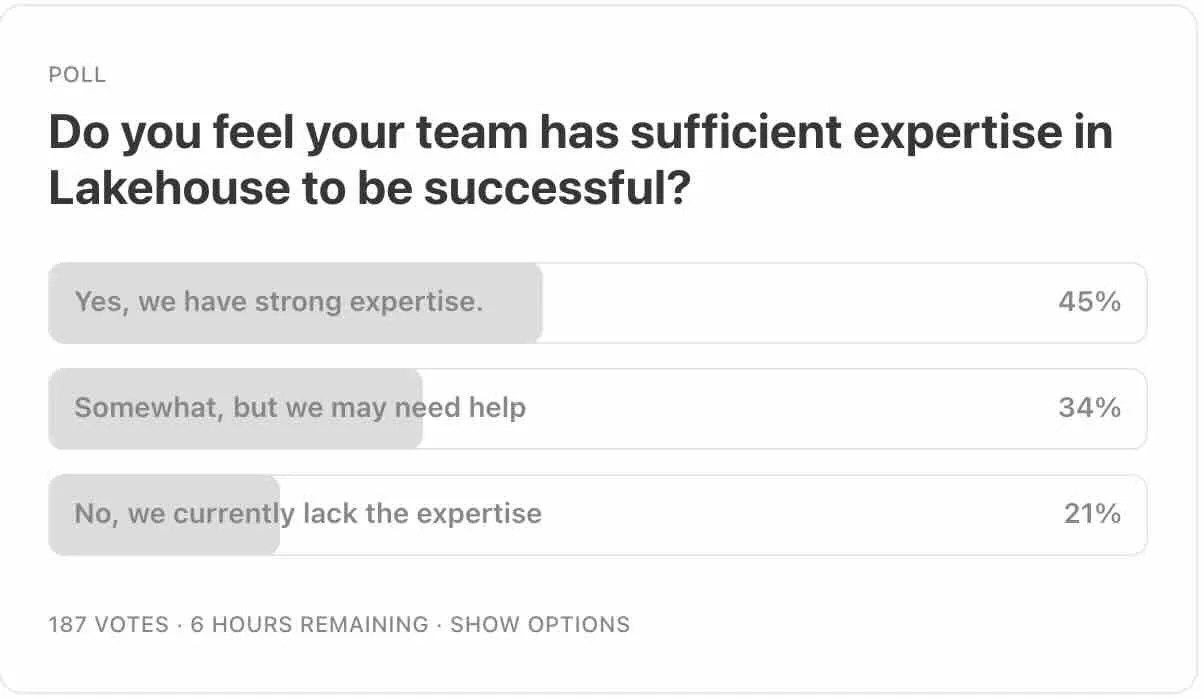
In one of our recent Data Engineering Surveys, we found that 91% of respondents said they were either using a lakehouse or looking to adopt it. At the same time, I’ve seen confusion around how to build a scalable and portable architecture. Only 45% of the responders said they have strong expertise in Lakehouse. Portability becomes the primary reason for an organization to adopt Lakehouse to control costs and improve flexibility.
Though every vendor claims to live and breathe the true spirit of the open standards, this is simply not possible in a growth-driven economy.
It leads to hidden vendor locks, which are hard to realize during the architecture design phase.
At the same time, I’ve seen cases where full-stack control outperforms open designs, especially when latency or SLA guarantees are non-negotiable. That’s why I think the anti-vendor-lock narrative is too one-dimensional.
Sometimes, a system performs more optimally when it has full control over the data and the process, which yields better system performance. Balancing both is the fine art of data engineering.
In this blog, I’m sketching my thought processes around building a portable data lakehouse architecture that balances vendor optimization and ecosystem openness.
The Foundational Layer of Data Infrastructure
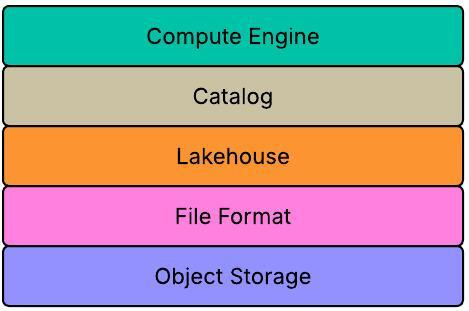
The foundational layer of the data infrastructure typically looks like this:
Object Storage houses all raw data.
File Format determines how that data is physically laid out (e.g., Parquet).
Table Format adds transactional consistency, versioning, and other table-level abstractions on top of these files.
Catalog keeps track of metadata, table schemas, partitions, and discoverability across the organization.
Compute Engine (Spark, Flink, Trino, etc.) consumes data from the catalog and storage layers to execute transformations and queries.
Note:
I’ve excluded data ingestion, transformation, and orchestration from this design. I consider them the “Supporting Layer” of the data infrastructure. The “Consumption & Discovery Layer,” such as BI tools and notebooks, is also excluded from the scope of this design. Both of them require a separate reference architecture guide.
A Reference Architecture for Foundational Layer

Object Storage & File Format
The decision about object storage and file format is more or less straightforward. Your choice of cloud providers determines the choice of the Object storage, and Parquet is a standard file format for storing tabular data in a columnar format. Though there are upcoming file formats like Nimble, Parquet enjoys best-in-class support from the table formats.
Lakehouse
The choice of Lakehouse is one of the industry's hotly debated and analysed topics. I’m not going much further here, as different companies have different preferences. Some might evaluate the number of vendors supporting a format, some based on the integrated experience to build productivity, or some evaluate specific use cases to see which Lakehouse provides the best performance.
Buy vs Build
Buy vs Build is one of the most frequently debated decisions when adopting new technology, and Lakehouse is no different. The complexity around table maintenance is no easy task as your data keeps growing. The choice depends on the business context, but I will always ask to understand the buy vs build decision better.
Is this a unique problem for us?Does building in-house provide a business competitive advantage?Has anyone solved this problem at our scaleWhat is the integration complexity to our existing infrastructure if we buy
The majority of us choose to buy as the complexity grows. The vendor choice for Delta Lake (Databricks) and Apache Hudi (Onehouse) is straightforward. Depending on your selection criteria, this can be a good or bad. The complexity of the architecture mostly comes when you have more than one choice of a system.
If you choose Iceberg or you’re looking to adopt a multi-lakehouse format, let's examine the system design more closely with the choice of the catalog design.
Catalogs & Query Engine
Catalogs are integral to the modern Lakehouse architecture, particularly due to their embedded transaction support and table management capabilities within specifications like Apache Iceberg. This centrality has fostered a diverse ecosystem of catalogs and vendors, underscoring the importance of thoughtful system design to ensure compatibility and performance. A subtle yet critical reality is that, although catalog and query engine technologies often appear distinct in architecture diagrams, their effectiveness hinges on tight integration.
A few interoperability questions become evident while building the lakehouse.
Is my data portable to another engine to maintain the table so I won’t be vendor locked?Can I bring multiple compute engines to run atop my lakehouse to speed up the innovation?
Data Portability
The primary selling point of Lakehouse is that your data is portable and not tied to any closed format native to a proprietary database. It is true, but that doesn’t mean your data is easily portable to another vendor. Having an open data format is one thing, but continuous maintenance of the tables is another part.
My version of portability is that you have a user table in Lakehouse format. Catalog A manages the table maintenance. Can you flip the switch and say Catalog B to manage the table without data migration?
The Iceberg standardization spec opens many catalogs' implementations, making portability challenging. Switching a catalog runs a complete scan, which causes either data movement or an additional storage API call that adds to the bill. S3Table is another classic example of locking, where it systematically prevents other catalogs from managing the Lakehouse.
Query Engine Interoperability
The symbiotic relationship between query engines and metadata catalogs remains pivotal in modern data processing. Effective query optimization depends fundamentally on robust and detailed metadata, capturing essential aspects like schemas, partition boundaries, file-level statistics, and data distribution patterns. Leveraging this metadata, query planners can make precise, informed decisions—enabling key optimizations such as partition pruning, predicate pushdown, and selective file skipping. These optimizations dramatically reduce unnecessary I/O operations and computational overhead by intelligently narrowing the scope of data scans.
Moreover, query engines must adeptly handle variations in view definitions and SQL dialects across catalog implementations. Tight integration ensures accurate interpretation and consistent execution across diverse systems. Equally critical, catalogs vary significantly in access control mechanisms, requiring close collaboration to enforce security policies effectively at query time.
Real-time access to updated statistics, evolving schemas, and contextual security information ensures query plans remain performant and compliant as datasets expand and complexity grows. In large-scale environments, these incremental improvements in efficiency and security accumulate, leading to substantial reductions in query execution times and optimized resource utilization, underscoring the strategic importance of integrating query engines closely with metadata catalogs.
A Federated Catalog Design
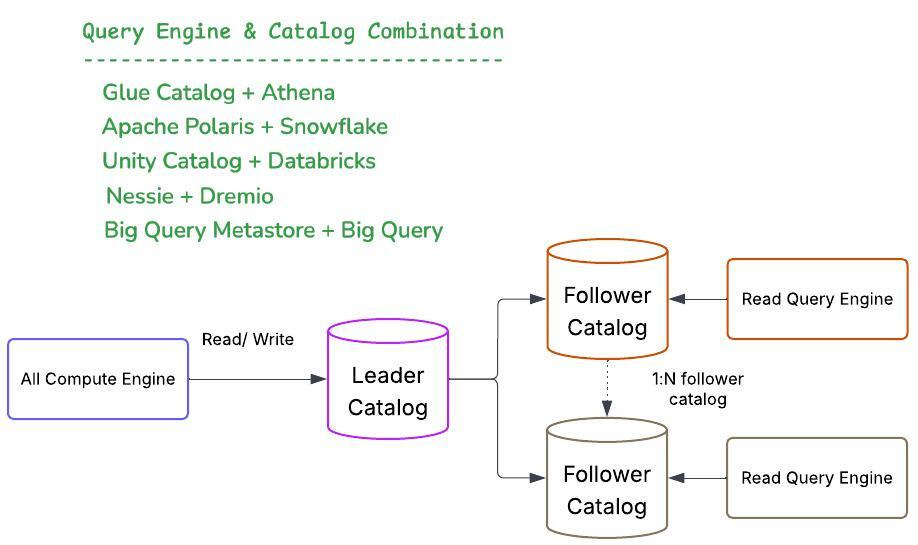
The federated architecture separates responsibilities between the write and read paths, significantly enhancing reliability and performance. By centralizing all write operations through a single catalog, organizations establish a unified source of truth for metadata, ensuring consistency, preventing synchronization conflicts, and simplifying critical tasks such as transaction management, schema evolution, and data quality enforcement.
On the read side, specialized, distributed read-only catalogs can cater specifically to individual query engines. This targeted approach allows each catalog to optimize metadata translation, effectively handling variations in SQL syntax and view definitions across different engines. Such engine-specific metadata tailoring enables more precise query planning and optimization. Additionally, these read-only catalogs can implement security and access control policies aligned precisely with their corresponding query engines, providing consistent and effective governance.
This federated, write-once-read-many approach strikes a strategic balance between consistency and optimization. Delineating write and read responsibilities fosters seamless interoperability among diverse tools and engines, each interacting with data via tailored interfaces. At the same time, the underlying metadata remains centralized, consistent, and robustly managed.
The Case for a Catalog Replicator
A purpose-built "Catalog Replicator" system is essential to realize this federated architecture's full potential. This specialized tool would serve as the critical infrastructure component that addresses the inherent complexities of maintaining a federated catalog ecosystem:
Intelligent Metadata Synchronization: The Catalog Replicator would propagate metadata changes from the primary catalog to engine-specific read-only replicas in near real time, implementing sophisticated change detection and efficient distribution mechanisms to minimize staleness.
Translation Layer: By incorporating a flexible translation capability, the replicator would transform catalog metadata between different formats and structures, ensuring each query engine receives metadata optimized for its specific requirements and capabilities.
Access Control Mapping: The replicator would maintain consistent security policies across catalog boundaries by implementing policy translation rules that map the primary catalog's access controls to their equivalent representations in each target catalog system.
Monitoring and Reconciliation: Automated verification processes within the replicator would continuously validate consistency between catalogs, detecting and resolving discrepancies to maintain system-wide integrity.
Schema Evolution Coordination: The replicator would orchestrate complex schema changes across the catalog ecosystem, ensuring that all read-only catalogs appropriately reflect and accommodate evolutionary changes while respecting the capabilities of their associated query engines.
This Catalog Replicator represents a critical enabling technology for federated catalog architectures. It transforms what would otherwise be a collection of implementation challenges into a systematic, managed solution that delivers on the promise of true interoperability.
Conclusion
We've been down the "one catalog to rule them all" path. Hive Metastore emerged as the de facto standard catalog for the Hadoop ecosystem, but its limitations became increasingly apparent as query engines evolved. Despite widespread adoption, Hive Metastore struggled to keep pace with the specialized metadata requirements of modern query engines, forcing uncomfortable compromises between compatibility and optimization.
The industry responded by creating specialized catalogs – but that pendulum swung too far, fragmenting metadata management and creating silos. A federated approach represents the thoughtful middle ground we've been searching for. It acknowledges the need for specialized metadata optimization and its critical importance.
As our data systems grow in scale and complexity, architectural approaches that balance specialization with consistency will prove increasingly essential. The federated catalog pattern, enabled by robust replication technology, represents exactly the kind of pragmatic innovation that mature data platforms need – one that enables continued innovation in query processing while maintaining the interoperability and governance that enterprises require.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.