


Unlocking data stream processing [Part 3] - data enrichment with fuzzy joins
By Olivier Ruas


Put yourself in the shoes of an IT department employee working for a large company. The finance department has requested your assistance with their annual balance sheet, explicitly matching all entries from the company's bank account with receipts submitted by employees for their professional expenses. Your colleague, Helen from finance, optimistically informs you that this should be easy since all the data has been entered into the company's databases.
However, upon examining the bank statements and receipts tables, you quickly realize that matching these entries will be far from straightforward:
Banking table: a table with schema automatically generated by the bank (later referred to as Table_banking_index). Great!

Receipt table (later referred to as table_receipts_index):

It turns out that all the receipts were manually entered into the system, which creates unstructured data that is error-prone. This data collection method was chosen because it was simple to deploy, with each employee responsible for their own receipts. Unfortunately, this approach results in unstructured data that is difficult to work with.
For example, here are some rows corresponding to your colleague Elizabeth:

Try to perform a regular join in this situation: it will be impossible due to the unstructured nature of the data. This is not uncommon in the banking industry, as an estimated 80% of banking data is unstructured. Additionally, different banking systems may use other naming conventions, further complicating data-matching efforts. In this context, making a regular join in this context is impossible. You must manually join these tables or ask employees to enter their receipts again following a specific schema. In both cases, it will be tedious and very frustrating.
Luckily, there is a solution: fuzzy joins.
In this article, we'll delve into the world of fuzzy joins and explore how they can help you make the most out of your data. Fuzzy joins provide an efficient solution for dealing with dirty and incomplete data. Enriching and cleaning the data through fuzzy joins can save time and reduce frustration while gaining valuable insights and discovering hidden patterns that can help drive business decisions. You’ll also see how Pathway, a Python framework for streaming data, can do real-time fuzzy joins. So, let's dive in!
Approximate matching with fuzzy joins
Fuzzy join is a data enrichment technique that allows you to match data based on approximate rather than exact matches. Fuzzy join enables you to perform data joins even if your data contains misspellings, typos, or other variations. With fuzzy join, you can uncover hidden patterns, identify new opportunities, and make better decisions.
Data enrichment is crucial because it is what turns raw data into pure gold. By adding new information or filling in missing data points, data analysts and engineers can enhance their datasets and gain new insights that would be impossible with raw data alone. However, as we have seen previously, data enrichment is often tricky and time-consuming, especially when dealing with messy or incomplete datasets. Joining tables with typos or simply different formats can be challenging. Fortunately, fuzzy joins allow you to match data based on approximate rather than exact matches and uncover hidden patterns.

In our previous example, we would like to have the following matchings:

Such matching is impossible with a traditional join, as the entry “James P.: Cloud services $5048” does not match any of the values in the different columns of the associated row in the banking table. Worse, the name is incorrect, “James P.” instead of “James Paletta.” The only correct value is the amount, which may not be unique in the table: there is no easy way to match without approximation.
That’s where fuzzy join comes in: the power of fuzzy join lies in its ability to match data based on similarity rather than exactness. Fuzzy join considers variations in the spelling, word order, and other factors to find possible matches between datasets. This means that fuzzy joins can still find meaningful relationships between data points even when the data is messy or incomplete.
Fuzzy join relies on different approximations, determining its success:

You can learn more about how fuzzy join works in this article which describes different types of fuzzy joins.
Using those approximations, a system using fuzzy join can overcome the most common hardships:

Those approximation techniques allow fuzzy joins to be applied to various data types, including text, numeric, and geographic data. This allows data analysts and engineers to choose the best matching method for their specific use case and achieve the most accurate results.
Exploring the diverse applications of fuzzy join
Fuzzy joins have applications beyond accounting. This technique is widely used across industries to enhance data quality and usability by uncovering hidden patterns.
One common use case for fuzzy joins is tracking a single entity across multiple tables, which is particularly useful for fraud detection and loan prediction in the banking sector. Fuzzy joins can identify suspicious transactions and accounts by matching data from various sources, such as credit card transactions and social media profiles. In addition, fuzzy join is used in marketing to improve customer segmentation and achieve a unified view of customers. For example, all articles related to a particular company can be automatically grouped using fuzzy join:
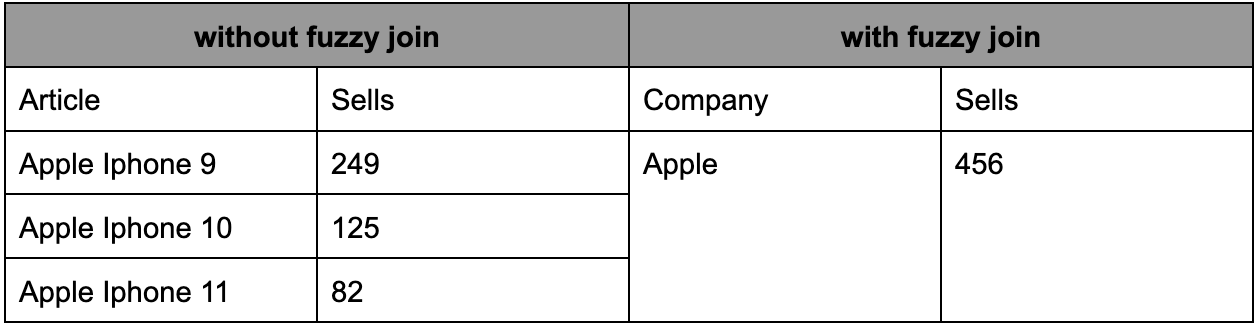
The limits of fuzzy join
While fuzzy joins are a powerful and versatile tool for data enrichment, there are some potential drawbacks.
One of the main challenges with fuzzy joins is determining an appropriate level of fuzziness or approximation. If the threshold is too high, the resulting matches may be too broad and include false positives. Setting the threshold too low may exclude relevant data points. Finding the right balance can require some trial and error and may be time-consuming.
The Thomson and Thompson case
An example of how fuzzy joins can lead to false positives is matching Jon Thomson in York (UK) with John Thompson in New York (US). However, it's essential to remember that homonyms are not unique to fuzzy join and pose a challenge for standard joins.
Performance cost
Another potential issue is the computational cost of fuzzy joins. Depending on the size and complexity of the matched datasets, the process can be resource-intensive and time-consuming. This can be especially problematic for organizations with limited computing resources or time-sensitive projects.
Precision matching for regulatory datasets
In addition, fuzzy joins might not be appropriate for certain types of data or use cases. For example, a more precise matching method might be necessary if data accuracy is critical (e.g., in medical or financial contexts). Fuzzy joins might also struggle with highly complex or unstructured data.
Realtime fuzzy joins with Pathway.
After you have accomplished the fuzzy join for Helen, the head of the finance department is impressed with the results and decides to integrate the fuzzy join process into the organization's daily operations. The finance team handles a substantial amount of data from the entire group daily. The finance head emphasizes that this data needs to be up-to-date so the team can make informed decisions based on accurate information.
This scenario is very different from previously regarding data volume and time: you have to perform a real-time fuzzy join on streaming data.
Since fuzzy joins are resource-intensive, they bring their own challenges in this streaming context. Every new data entry alters the fuzzy join results, necessitating frequent recomputations. Such batch processing on a streaming database is resource-intensive.
However, there is a solution: Pathway, a Python framework for real-time data stream processing that automates the updates. With Pathway, you can set up your processing pipeline and request a fuzzy join. The platform will ingest new streaming data points for you, keeping the fuzzy join updated without recomputing everything from the beginning.
Using Pathway's connectors, you can create two tables with two input streams, one from the bank and one from the receipts, and then easily perform a fuzzy join between them:

It's straightforward and is done in a single operation, just like a regular join. Furthermore, the three tables are updated accordingly as new data points are received. This means that the matching table is adjusted to reflect any new data that comes in.
Check out Pathway's fuzzy join example to see how this works in practice.
Fuzzy join is a “smart replacement” for traditional joins that can handle discrepancies in data. Smart replacements are techniques used in computer science to improve the performance and accuracy of an operation. They're designed to make tasks more efficient and effective by providing innovative solutions to common problems.
Pathway offers several smart replacements for typical table operations:

These smart replacements allow you to enrich your data easily. Pathway can update its results in real-time, providing better performance than traditional methods.
Conclusions
Data enrichment is a powerful tool that turns raw data into a treasure trove of valuable insights. By filling in missing data points and adding new information, data analysts and engineers can uncover hidden patterns and gain new perspectives that would be impossible with raw data alone.
However, data enrichment can be tricky and time-consuming, especially when dealing with messy or incomplete datasets. That's where fuzzy joins come in. These powerful tools allow you to match data based on approximate rather than exact matches, making it easier to uncover patterns and gain insights from your data.
Whether you're working in finance, marketing, or any other field that deals with data, fuzzy joins can help you overcome the challenges of messy or incomplete data and make the most of your data. And with tools like Pathway, you can even perform fuzzy joins in real-time, keeping your data up-to-date and accurate without wasting precious resources.
So if you want to get the most out of your data and gain new insights that will help you make better decisions and drive business growth, give fuzzy joins a try. You'll be amazed at what you can discover with the right tools and techniques!
Don’t hesitate to contact us on our discord server if you have questions about fuzzy join or smart replacements.