
What “Supporting Our AI Overlords” and “Semantic Spacetime” Tell Us About the Future of Data Infrastructure
Connecting agent-first and universal semantic grammar to reimagine data infrastructure beyond the relational model.

Last week, I came across two papers that altered my perspective on the future of data infrastructure: “Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First and Agent Semantics” and “Semantic Spacetime, and Graphical Reasoning.” Reading them back-to-back felt like stepping out of a familiar city grid and realizing the world is actually a dense, living forest. One paper examined the interaction of AI agents with data, while the other proposed a radically simple grammar for structuring meaning and reasoning. Put together, they made me rethink the future of the data warehouse and how radically different it could look from the systems we build today.
The Data Warehouse We Know
The traditional data warehouse was born in an era when humans were the primary consumers of data. It was designed for analysts, managers, and decision-makers who knew their business questions in advance and needed reliable answers from well-modeled data. Picture a financial analyst who needs to prepare a quarterly report: they connect to a BI tool, run a set of SQL queries against carefully curated tables, and trust that the joins and aggregations will give them consistent results. The entire design of the system is based on stability, predictability, and precision.
Relational warehouses excel at this. Schema-first design ensures that the data model aligns with the business logic. Queries are precise and deterministic. Rollbacks are rare because transactions are meant to succeed, and if something goes wrong, it’s exceptional. Performance optimization focuses on extracting milliseconds from a stable workload. In short, the warehouse is a fortress of order and reliability.
But then agents arrived — and they play by different rules.
The Agent-First Vision
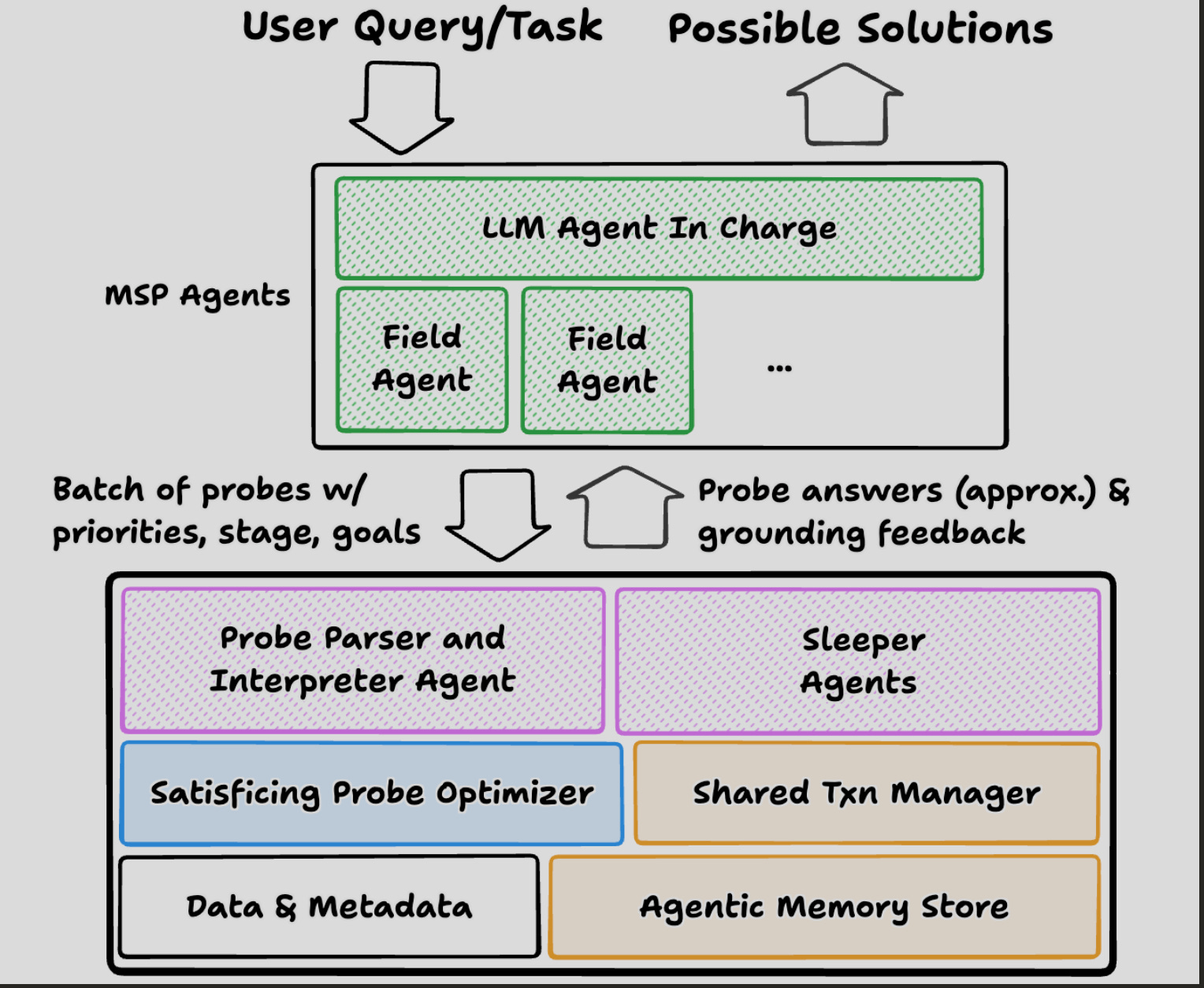
The first paper, Supporting Our AI Overlords, argues that data systems must be redesigned to be agent-first. Unlike humans, agents don’t ask a handful of well-formed queries. They speculate. They explore. They generate thousands of requests, often redundant, often overlapping, many of which lead nowhere. In this world, a single optimized query plan isn’t enough. What we need are probe optimizers that satisfice across a swarm of lightweight requests, merging commonalities, pruning unnecessary work, and allowing approximation where possible.
Agents also need memory. Without it, they waste cycles rediscovering schema information or repeating the same failed attempts. Agentic memory becomes a shared cache of grounding — hints about which tables connect, patterns of successful queries, and common keys. This reduces waste and makes speculation sustainable.
Most importantly, agents live in a world of branching and rollback. They don’t just test one idea; they fork dozens of potential futures. Some will hit dead ends quickly, and others will need to be explored further. Rollback is not an exception here — it is the norm. That requires an entirely new transaction model, one where branching is cheap and rollback is almost free.
This is a profound inversion of the relational mindset. Instead of stability first, we design for exploration. Instead of treating rollbacks as rare, we assume they are a constant occurrence. Instead of optimizing for precision, we optimize for flexibility and satisficing. That’s what it means to be agent-first.
Semantic Spacetime: The Missing Grammar

Speculation alone isn’t enough. Agents require a semantic foundation that enables them to reason. This is where the second paper — Agent Semantics, Semantic Spacetime, and Graphical Reasoning — completes the picture.
SST proposes a universal grammar where the world is described in terms of events (ephemeral), things (persistent), and concepts (abstract). These connect through just four fundamental relations:
NEAR: similarity or proximity.
LEADS TO: causality or sequence.
CONTAINS: aggregation or membership.
EXPRESSES: attributes or properties.
With these primitives, reasoning becomes a flow through a graph. Finding similar past cases is a NEAR traversal. Building a causal explanation is a LEADS TO chain. Evaluating whether an itinerary works is a CONTAINS check. Checking risk is an EXPRESSES annotation. And when a path collapses, it’s simply an absorbing state — a natural endpoint, not a failure.
This universal grammar provides agents with a foundation for exploration that aligns with their behavior. It strips away the brittle schema complexity of relational systems and replaces it with a flexible structure for speculative reasoning.
Why Agents Break Current Workflows
Imagine this: your flight from New York to San Francisco gets canceled because of weather systems sweeping across the Midwest. Suddenly, you need to find an alternative route to reach SFO quickly. This is the kind of real-world scenario where the cracks in current workflows become painfully visible. To illustrate the impact, let’s revisit the concrete scenario of a flight delay and reroute.
In a relational world, a human ops manager queries the Flights table to confirm the delay. They join with the Weather and ATC tables to check causes. They query Connections and Schedules to explore downstream impacts. If they want to propose reroutes, they test one or two manually by writing new queries. Each step requires schema knowledge, careful joins, and multiple handoffs. If an option fails, they backtrack, clean up, and try again.
For an agent, this is untenable. Instead, the agent detects the delay event and instantly issues probes: finding similar past delays (NEAR), inferring the causal chain (LEADS TO), generating alternative itineraries (CONTAINS), and annotating risks (EXPRESSES). It forks dozens of speculative reroutes, automatically prunes infeasible ones, and rolls back dead ends with no cost. In parallel, it scores surviving options and proposes the best route for human approval.
The contrast couldn’t be sharper. To make this tangible, let’s walk step by step through how a human analyst would handle the canceled New York to San Francisco flight, compared with how an agent-first system would respond:
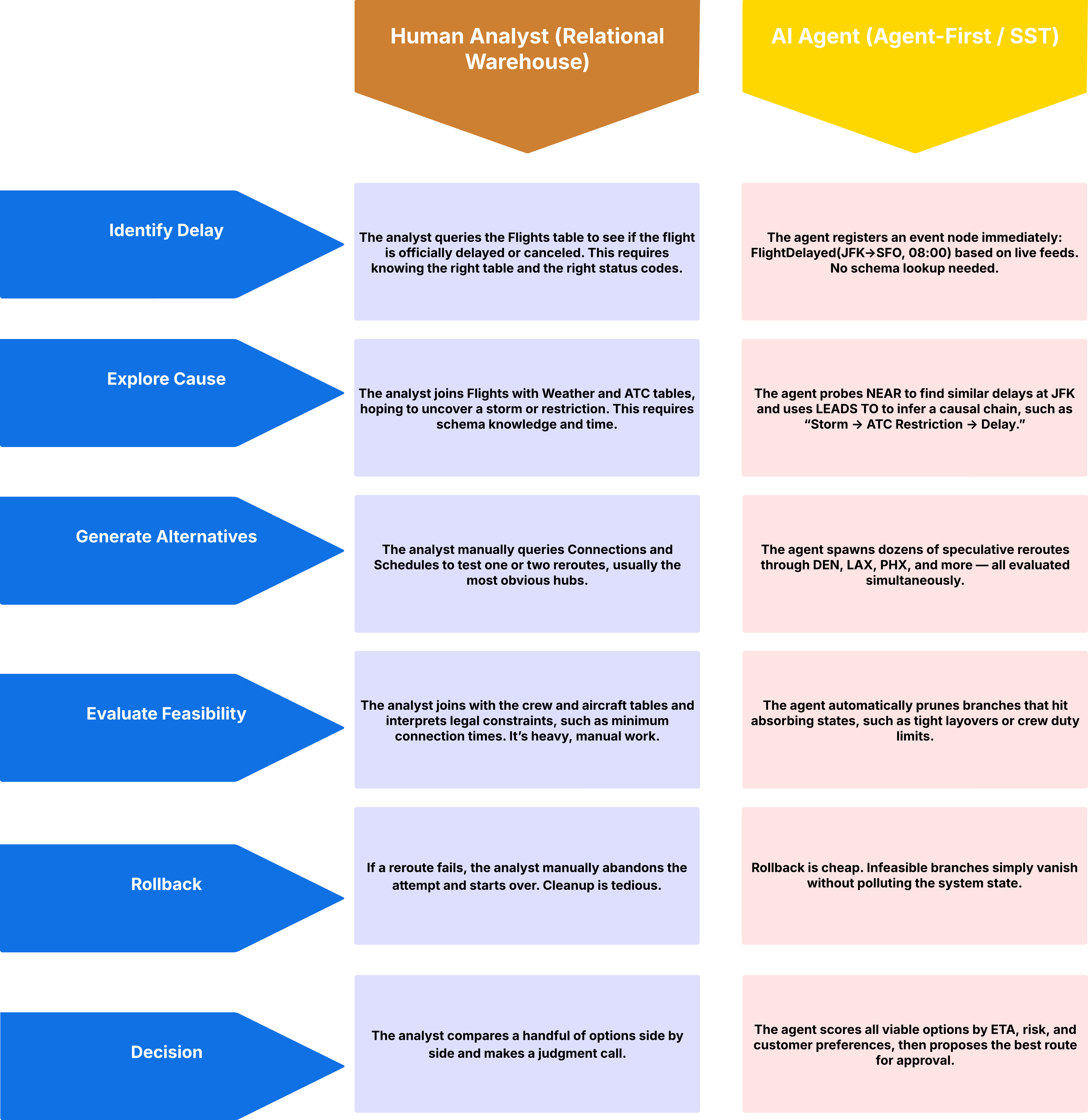
Each row in this table represents more than just a workflow difference — it represents a philosophical divide. Humans make queries deliberately, with cost in mind. Agents speculate freely, with pruning and rollback built into their DNA. Historically, bridging this gap required building dedicated AI applications, with teams writing custom middleware to mimic speculation and state management. That level of engineering effort is unsustainable at scale. Agents demand infrastructure that enables speculation as a native capability, not a bolt-on hack.
Why MCP Shows Promise But Still Has Fundamental Limitations
 and How It Works")
It’s tempting to believe that Multi-Call Protocols (MCP) and tool integration layers solve the agent-data mismatch problem. Recent developments have indeed expanded MCP’s capabilities significantly—MCP has “evolved significantly beyond its original goal” and now supports “resumable streams, elicitation, sampling, and notifications” for more sophisticated agent interactions. These enhancements enable some forms of agent-to-agent communication and longer-running workflows that weren’t possible in MCP’s initial design.
However, these improvements don’t address the fundamental architectural mismatch. Research from Microsoft confirms that while “horizontal integration is expanding capability,” it also “exposes forms of toolspace interference that can erode end-to-end effectiveness“. The core issue remains: MCP still primarily exposes existing APIs—precise, single-purpose endpoints designed for human or application use—to agents that operate fundamentally differently.
Here’s the deeper problem: speculation generates “hundreds of overlapping, approximate requests,” and “MCP servers do not know which clients or models they are working with, and present one common set of tools, prompts, and resources to everyone.” Even with streaming and resumable sessions, each speculative branch still becomes an API call, each rollback still represents wasted computation, and each probe still triggers an expensive round-trip.
The protocol improvements help with session management and real-time communication. Still, they don’t solve the satisficing problem—the need for systems that can reason about approximate answers across thousands of overlapping requests. As Microsoft’s research notes, this “places MCP at a disadvantage over vertical integrations that optimize to the operating environment”.
Think of it like trying to explore a forest with a city map that now has better GPS updates and turn-by-turn directions. The improvements are real and valuable, but the fundamental mismatch between the structured, predetermined paths of the city and the organic, branching exploration patterns needed in the forest remains. MCP can provide better entry points and communication channels, but it can’t adapt the underlying infrastructure to support the speculative, satisficing behavior that agents naturally exhibit.
To truly support agents, we need systems built for their mode of reasoning from the ground up—probe optimizers that can merge commonalities across speculative requests, agentic memory that shares grounding across attempts, and storage systems where branching and rollback are first-class citizens, not expensive exceptions.
Engineering Implications: ETL, Optimizers, and Modeling
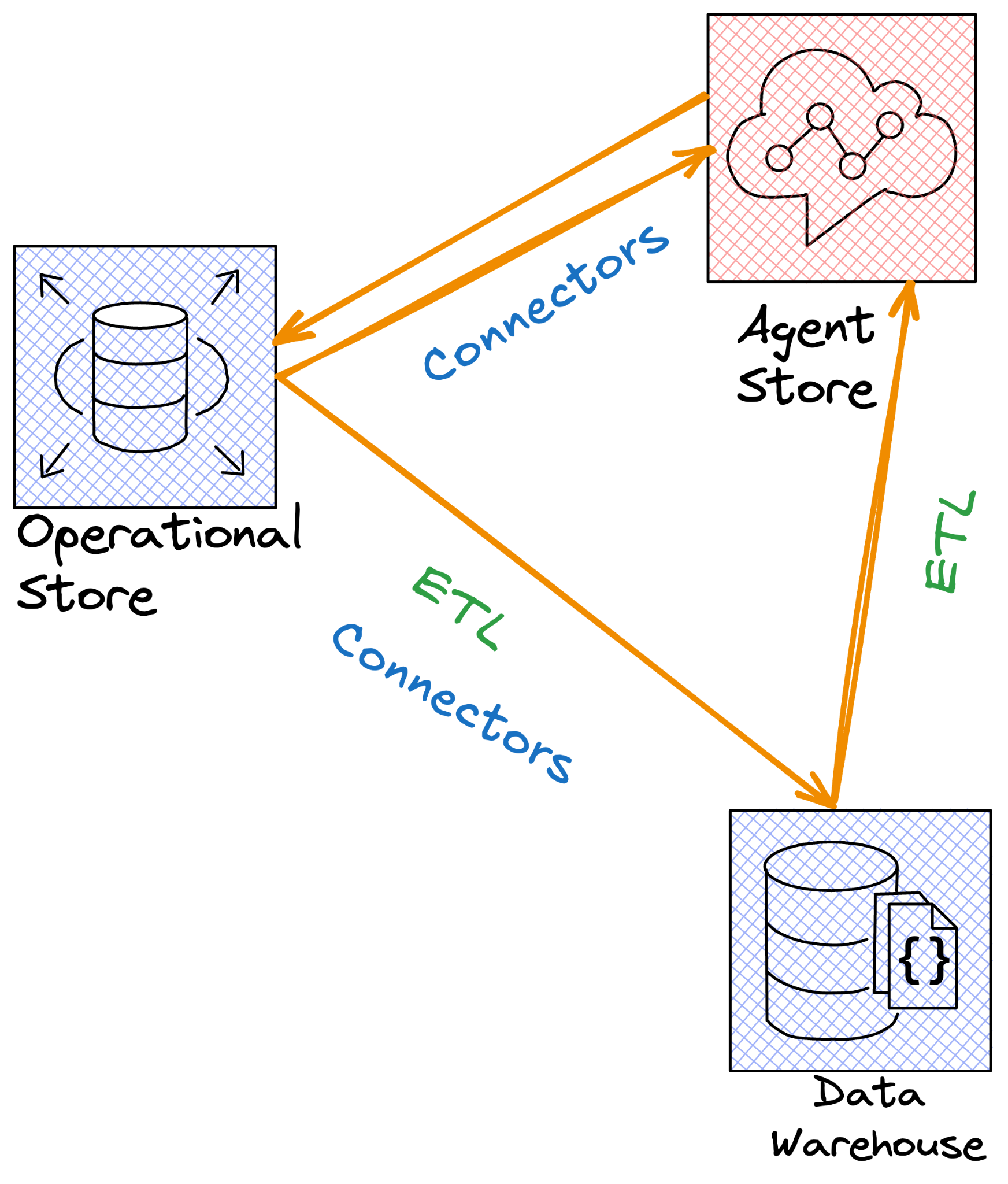
What does this shift mean for engineers on the ground? A lot.
ETL Pipelines: Traditional ETL is built on the assumption of stable schemas and batch transformations. In an agent-first world, pipelines must evolve to ingest streams of events and relationships into flexible graph models. The focus shifts from building rigid star schemas to feeding a semantic substrate that supports speculative reasoning.
Query Optimizers: Current optimizers are masterpieces of cost-based precision for a single query. Probe optimizers must operate differently; they satisfice across thousands of overlapping requests, deduplicate work, prune early when thresholds are met, and tolerate approximation errors. Optimization becomes orchestration of exploration, not just plan selection.
Data Modeling: Analysts love snowflake schemas because they map cleanly to reports. Agents don’t. They need universal semantics like SST. Modeling shifts from focusing on dimensions and facts to encoding events, things, and concepts in a graph that supports dynamic traversal.
Rollback Semantics: Rollback is an exception today. For agents, it’s constant. Engineers will need to adopt copy-on-write models, multi-version concurrency, and branching as core primitives. This is not middleware; it’s foundational.
Together, these implications suggest a wholesale shift in engineering priorities. The agent-first warehouse is not just a bigger, faster relational system — it is a different species of infrastructure.
Closing Thoughts
When I first read these two papers, it felt like a shift in perspective. I realized that the future of the data warehouse isn’t about making SQL faster or schemas fancier. It’s about reimagining the warehouse as a place where agents speculate freely, prune dead ends, and discover causal flows — a semantic playground that sits alongside the stable ledger of truth.
If the relational warehouse was the city grid of data, the agent-first warehouse is the living forest. If we want to build infrastructure for the agents coming, we need to start planting the trees now.
Here are the questions I want to leave you with: If agents are going to be the primary users of data systems, do we believe our current warehouses are enough? What would it look like to build data systems where speculation is a first-class citizen? And if we don’t start building them now, what opportunities will slip through our fingers?
The shift will not be easy. It requires rethinking decades of assumptions about schemas, transactions, and optimization. However, the alternative is to cling to infrastructures designed for humans in a world where agents will increasingly navigate. The two papers I read last week didn’t just offer new frameworks; they offered a glimpse into that future. We can choose to treat them as academic exercises or use them as seeds for a new generation of data systems.
If the history of computing has taught us anything, it’s that those who anticipate the next dominant user — from terminals to GUIs to the web to mobile — shape the landscape for decades to come. Agents are the next user. The question is not whether they will need new data substrates, but whether we will be ready when they arrive.
References
Primary Sources
Burgess, Mark. “Agent Semantics, Semantic Spacetime, and Graphical Reasoning.” arXiv preprint arXiv:2506.07756, June 2024. https://arxiv.org/html/2506.07756
Chandramouli, Badrish, et al. “Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First.” arXiv preprint arXiv:2509.00997, September 2024. https://arxiv.org/html/2509.00997
Supporting Research and Analysis
Anthropic. “Introducing the Model Context Protocol.” Anthropic Blog, November 2024. https://www.anthropic.com/news/model-context-protocol
Microsoft Research. “Tool-space interference in the MCP era: Designing for agent compatibility at scale.” Microsoft Research Blog, December 2024. https://www.microsoft.com/en-us/research/blog/tool-space-interference-in-the-mcp-era-designing-for-agent-compatibility-at-scale/
Microsoft for Developers. “Can You Build Agent2Agent Communication on MCP? Yes!” Microsoft Developer Blog, July 2025. https://developer.microsoft.com/blog/can-you-build-agent2agent-communication-on-mcp-yes
AWS Open Source Blog. “Open Protocols for Agent Interoperability Part 1: Inter-Agent Communication on MCP.” AWS Blog, May 2025. https://aws.amazon.com/blogs/opensource/open-protocols-for-agent-interoperability-part-1-inter-agent-communication-on-mcp/
Technical Documentation
Model Context Protocol Documentation. “MCP Specification and Design Guides.”
https://modelcontextprotocol.io/
OpenAI. “Model context protocol (MCP) - OpenAI Agents SDK.” OpenAI Documentation. https://openai.github.io/openai-agents-python/mcp/
Industry Analysis
Lisowski, Edwin. “MCP Explained: The New Standard Connecting AI to Everything.” Medium, April 2025. https://medium.com/@elisowski/mcp-explained-the-new-standard-connecting-ai-to-everything-79c5a1c98288
Stream Blog. “Why Agents Need A2A and MCP for AI Solutions.” GetStream Blog, May 2025. https://getstream.io/blog/agent2agent-vs-mcp/
Outshift (Cisco). “MCP and ACP: Decoding the language of models and agents.” Outshift Blog, 2024. https://outshift.cisco.com/blog/mcp-acp-decoding-language-of-models-and-agents
Hugging Face. “What Is MCP, and Why Is Everyone Suddenly Talking About It?” Hugging Face Blog, 2024. https://huggingface.co/blog/Kseniase/mcp
Open Source Implementations
LastMile AI. “mcp-agent: Build effective agents using Model Context Protocol and simple workflow patterns.” GitHub Repository. https://github.com/lastmile-ai/mcp-agent
SpaceTime & Spacetimeformer - Transformer architectures for “multivariate time series forecasting” that learn “temporal patterns like a time series model and spatial patterns like a Graph Neural Network” https://github.com/HazyResearch/spacetime & https://github.com/QData/spacetimeformer
OpenSTL - A “Comprehensive Benchmark of Spatio-Temporal Predictive Learning” offering a “modular and extensible framework” for spatiotemporal prediction method https://github.com/chengtan9907/OpenSTL