
When Dimensions Change Too Fast for Iceberg
Why Iceberg Struggles with Fast-Changing Dimensions—and What Comes Next

Introduction
A customer’s loyalty tier changes mid-checkout. A fraud score recalculates between one transaction and the next. An ad audience reshapes itself in minutes. Modern data platforms must keep pace with this reality—yet they are built on the architectural promise of immutability. This tension between immutability and constant change defines the hardest challenge in today’s data systems.
Traditional slowly changing dimensions (SCDs)—such as marital status, store location, or product metadata—are well handled by table formats like Apache Iceberg. But fast-changing dimensions (FCDs) break the model. With millions of records shifting in near real-time, Iceberg’s immutable-append design collides with workloads it was never optimized to handle.
This article explores that collision. We’ll define the unique characteristics of FCDs, examine how practitioners implement them in Iceberg today, and analyze the challenges those approaches face. Finally, we’ll look at emerging architectures—including Apache Hudi, Apache Paimon, and DuckLake—that are redefining how real-time data fits into the Lakehouse. By the end, you’ll see why the next generation of data platforms must embrace both mutability and immutability at once.

What Are Fast-Changing Dimensions?
At their core, dimensions are the descriptive context for facts. A clickstream event that records “user clicked ad X at time T” is a fact. To make that fact useful, you enrich it with dimensions: who is the user, what is the ad, what campaign does it belong to, and what device did it occur on. Dimensions turn raw facts into interpretable business signals.
Traditionally, dimensions were assumed to be relatively stable. A product retains its SKU and category. A customer’s date of birth does not change. A store location only occasionally moves. For these kinds of attributes, the slowly changing dimension model works well.
Fast-changing dimensions break this assumption. They are defined not by their size but by their frequency of change and their business reliance on freshness.
Advertising and marketing rely on up-to-date audience membership. A customer who views a product should be added to a remarketing segment immediately, and if they make a purchase, they should be removed instantly. Stale membership means wasted spend.
Financial services recalculate credit scores and risk bands frequently. Fraud risk is recalculated with each new transaction, and regulators demand that you be able to reproduce the score “as of” the transaction date.
E-commerce personalization updates user cohorts continuously. Loyalty tiers, discounts, and eligibility rules all change with every interaction.
IoT devices report their states constantly. Whether a machine is “healthy,” “degraded,” or “offline” can change many times in a single day.
Telecom systems manage millions of subscriptions, with users moving between roaming, active, or suspended states dynamically.
The problem with fast-changing dimensions is that none of the traditional slowly changing dimension types scale cleanly. Type-1 overwrites discard history, which is unacceptable in regulated domains. Type-2 history preserves every state but quickly leads to explosive table growth as attributes change frequently. Type-3 patterns are too limited to capture the richness of real-world churn.
Fast-changing dimensions, therefore, require something different. They require systems that can ingest updates at very high velocity, provide accurate point-in-time views, and balance the cost of ingestion with the performance of queries. And this is precisely where the immutable-append model of Iceberg runs into friction.
This need for freshness, accuracy, and scale sets the stage for a closer look at the defining characteristics of fast-changing dimensions—and why they clash with current lakehouse designs.
Characteristics of Fast-Changing Dimensions
Fast-changing dimensions strain analytical systems because they update at a velocity most lakehouse formats were never designed to handle. Several key characteristics define these tables:
High Churn Rate: Millions of rows may be updated or deleted in an hour. Attributes like last_login_timestamp or current_status change constantly, creating pressure on write performance.
Low-Latency Requirement: Insights lose value if they arrive hours late. In advertising or fraud detection, queries must reflect changes within seconds or minutes—not after a nightly ETL job.
Temporal Correctness: Analysts need to know not just the current value, but what the value was at the time of the transaction. This is mandatory in regulated domains like finance.
High Cardinality: Dimension keys (e.g., user IDs, device IDs) often number in the billions. Naïve approaches such as full table scans for updates don’t scale.
Transactional Integrity: Each update carries business significance, so systems must capture every change reliably, without loss or corruption.
These properties clash with immutable, append-only lakehouse architectures. Designed for large, infrequent batch writes, they struggle when confronted with small, continuous updates at massive scale. To see this conflict in practice, we turn to Apache Iceberg, the most widely adopted lakehouse table format today.
Iceberg Today: Current Implementation Patterns
Iceberg was designed around the principle of immutability. Instead of mutating existing data files, it appends new files and uses metadata to present a consistent view. This design excels for analytical workloads but becomes awkward for FCDs.
To support updates, Iceberg uses deleted files. There are two types: equality deletes and positional deletes. Both are critical to understanding how FCDs are managed today.
Equality Deletes: Cheap to Write, Expensive to Read
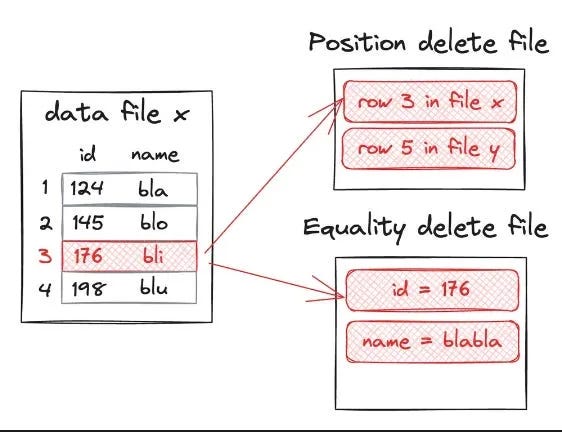
The most common technique in Iceberg today is the equality delete. When an update arrives, the writer appends a small delete file that says “drop any rows where user_id = 123.” This approach is appealing because it avoids rewriting the underlying data files. Writes are cheap, and streaming frameworks like Flink and Spark can generate these deletes easily.
The problem appears during reads. Query engines must scan candidate files, check each row against the equality delete conditions, and discard matching rows. As the number of deleted files grows, queries slow down significantly. Compaction jobs can collapse these deletes into consolidated data files, but that adds operational overhead.
Equality deletes are the default for streaming writers because they are simple, but they impose a heavy tax on readers.
Positional Deletes: Expensive to Write, Cheap to Read
The alternative is the positional delete. Instead of saying “delete all rows with user_id = 123,” the writer says “delete the row at position 4 in file A.” Readers can then skip exactly those rows without scanning.
Positional deletes make reads efficient, but generating them is difficult. Writers must know exactly which file and which row position the old record resides in. In batch MERGE jobs, this is feasible because the engine is scanning the data anyway. In streaming scenarios, it is nearly impossible because the system lacks continuous knowledge of row positions.
Thus, positional deletes are primarily used in batch compaction jobs rather than in real-time streams.
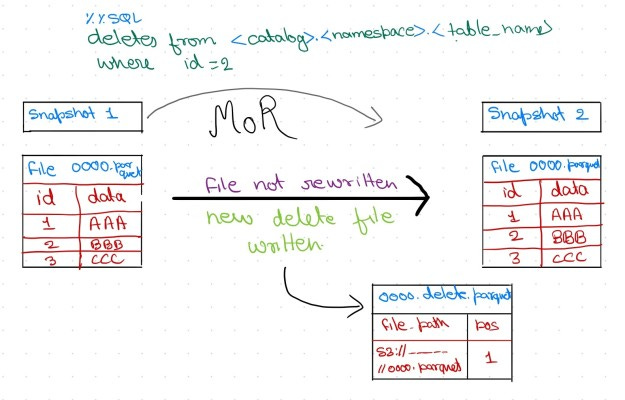
Buffered MERGE: The De Facto Approach
Given the limitations of both delete types, many production teams adopt a buffered MERGE pattern. They capture updates into a staging table, and then periodically run a batch MERGE job with Spark or Flink. The job scans the staging table, joins against the dimension table, and writes out new data files plus the appropriate delete files.
This approach works and produces correct results, but the batch interval bounds the latency. If the MERGE job runs hourly, then the dimension table is at least an hour out of date. For some use cases, that is acceptable; for FCDs, it is often not.
Medallion Layering: Bronze, Silver, Gold
Many teams wrap these mechanics in a medallion architecture. Bronze holds raw events, Silver holds deduplicated and historized dimension states, and Gold holds point-in-time snapshots optimized for joins. This layering isolates complexity but does not eliminate it.
Together, equality deletes, positional deletes, buffered MERGE jobs, and medallion layering define the current ceiling of what Iceberg practitioners do to manage fast-changing dimensions. It works, but it is far from ideal.
These patterns highlight Iceberg’s limits—and naturally raise the question: where exactly do they break down, and why?
Challenges with Iceberg for FCDs
The patterns described above all function, but each carries challenges that make them difficult to scale for FCDs.
1. Equality Delete Overhead
Equality deletes accumulate quickly in FCD workloads. A user flipping segments ten times an hour creates ten delete records. Multiply this by millions of users, and you generate millions of deleted files. Readers must evaluate these files, which can lead to degraded query performance.
2. Positional Delete Limitations
Positional deletes solve the read problem but create a write problem. You must know the exact row position of the old record, which streaming systems do not track continuously. Generating positional deletes in real time is effectively impossible without an auxiliary index.
3. Lack of True Upserts in Streaming
Most streaming sinks for Iceberg — in Flink, Spark, or Trino — do not support native upserts. They append data and write equality deletes. Upserts must be emulated by periodic batch merges, which introduce latency.
4. Compaction Pressure
Compaction jobs must run aggressively to collapse and delete files. Without them, queries grind to a halt. But compaction consumes compute and storage, creating a trade-off between freshness and cost.
5. Serving Gap
Iceberg provides excellent analytical snapshots, but cannot provide millisecond lookups for operational systems. Fast-changing dimensions often need both — low-latency serving for online use cases and historization for analytics. Iceberg alone cannot meet both requirements.
These limitations explain why so much innovation is now happening outside Iceberg—and why alternative architectures are emerging to fill the gaps.
Emerging Architectures
Hudi and Paimon: Write-Optimized Lakes
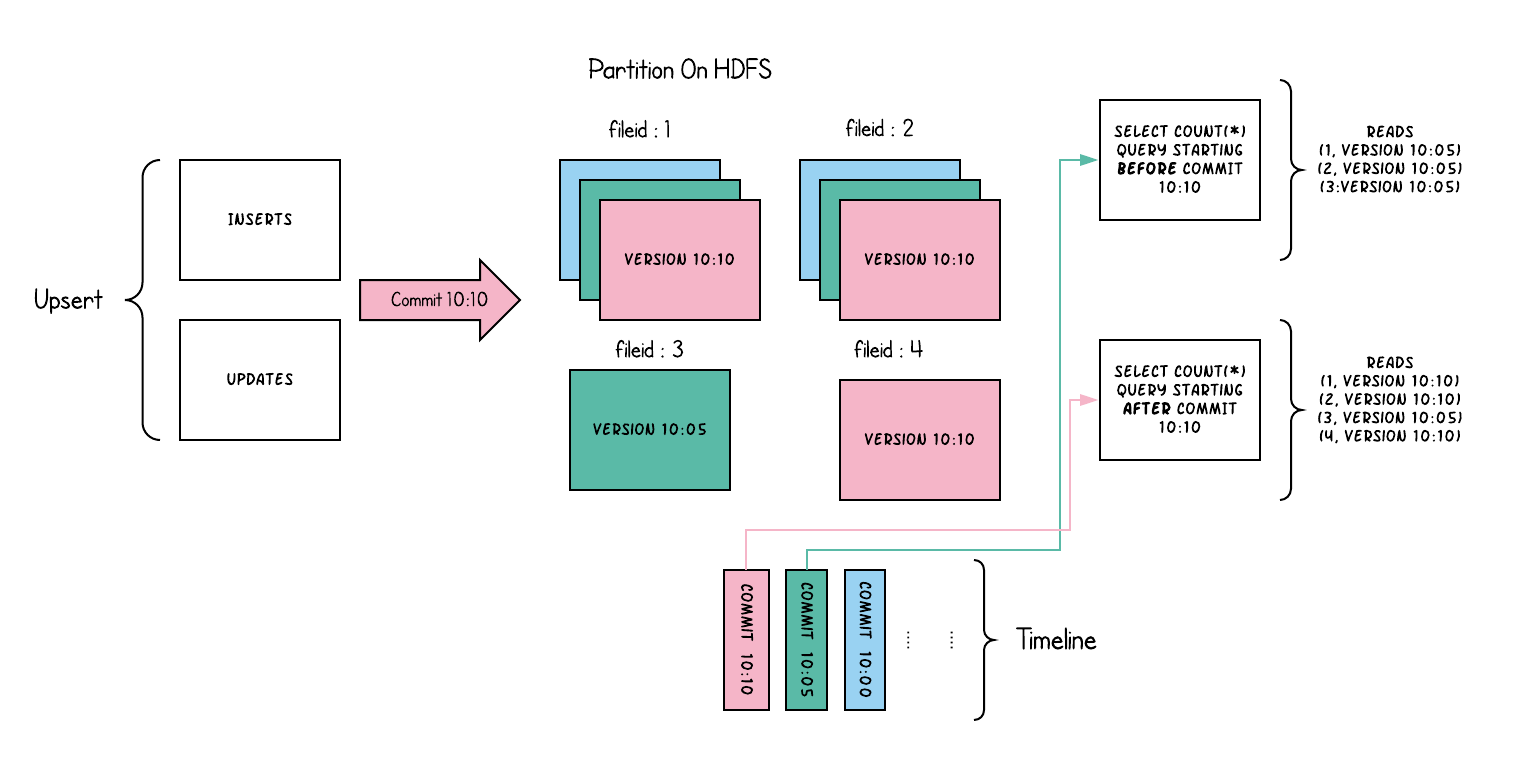
Apache Hudi and Apache Paimon were both designed with mutable data as a first-class concern. They use a log-structured merge (LSM) approach that allows for true upserts.
When an update arrives, Hudi or Paimon does not rely on equality deletes. Instead, the system writes the new record into a delta log file. Readers merge the base file and the delta log on the fly, ensuring that queries see the latest version. In the background, compaction rewrites logs into new base files.
This design mirrors LSM trees in databases: cheap writes, deferred compaction, and merged reads. It allows Hudi and Paimon to absorb high-churn updates without staging.
Both systems also provide indexing mechanisms. Hudi uses Bloom filters, bucket hashing, or metadata tables to locate which file a record belongs to. Paimon uses key-range partitioning with changelog streams. These indexes allow the system to direct updates to the correct file groups.
The benefits are significant:
True upserts without external buffers.
Incremental queries that pull only changes since the last commit.
Streaming-native ingestion with Flink or Spark.
But there are trade-offs. The ecosystems are smaller than an Iceberg. Query engine integration is improving, but not as broadly. Compaction remains a necessary cost. And many enterprises that standardize on Iceberg mirror their Hudi or Paimon tables into Iceberg for interoperability.
Thus, Hudi and Paimon represent a write-optimized lake layer, often paired with Iceberg for read-optimized analytics. In short, Hudi and Paimon put writes first. For teams chasing freshness, they offer an attractive complement to Iceberg’s analytical strengths.
The Federated OLAP-Lakehouse: A Hybrid Approach
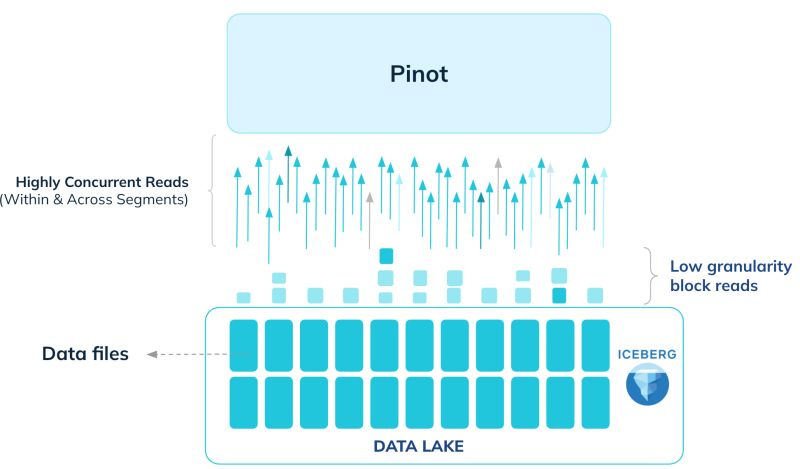
This emerging architecture combines the strengths of a real-time OLAP store with a traditional data lakehouse, using a federated query engine to provide a unified view. It acknowledges that a single system may not be optimized for all types of data and workloads.
The Architectural Pattern
The core idea is to handle different data based on its characteristics:
Fast-Changing Dimensions in an OLAP Store: High-churn, high-cardinality dimension tables (e.g., user status, inventory levels) are ingested into a specialized OLAP database like Apache Druid, Apache Pinot, or ClickHouse. These systems are designed for rapid ingestion and extremely low-latency lookups on the most recent data.
Large-Scale Facts in the Lakehouse: Massive, historical fact tables remain in an open format like Apache Iceberg. This provides cost-effective storage and transactional guarantees for the bulk of the analytical data.
Unified Queries with a Federated Engine: A query engine like Trino sits on top, acting as the universal translator. When a user runs a query, Trino intelligently pushes down parts of the query to the OLAP store (to fetch the dimension data) and other parts to Iceberg (to scan the fact data). It then performs the final join, returning a single, cohesive result to the user.
This federated architecture offers a powerful, best-of-breed solution by pairing a real-time OLAP store for fast-changing data with a cost-effective lakehouse for historical facts, all unified by a single SQL interface. The primary advantages include optimized performance through the use of the right tool for each job and a simplified query experience for end-users. However, this approach comes with significant trade-offs, most notably the high operational complexity of managing three distinct distributed systems. Furthermore, it introduces challenges in maintaining data consistency across separate stores and can create network bottlenecks when the federated engine performs large-scale joins between the OLAP and lakehouse systems.
This hybrid model highlights a growing theme: rather than stretching one system to do everything, architects are increasingly combining specialized systems for each workload.
Augment Iceberg: Real-Time Positional Deletes with External Index
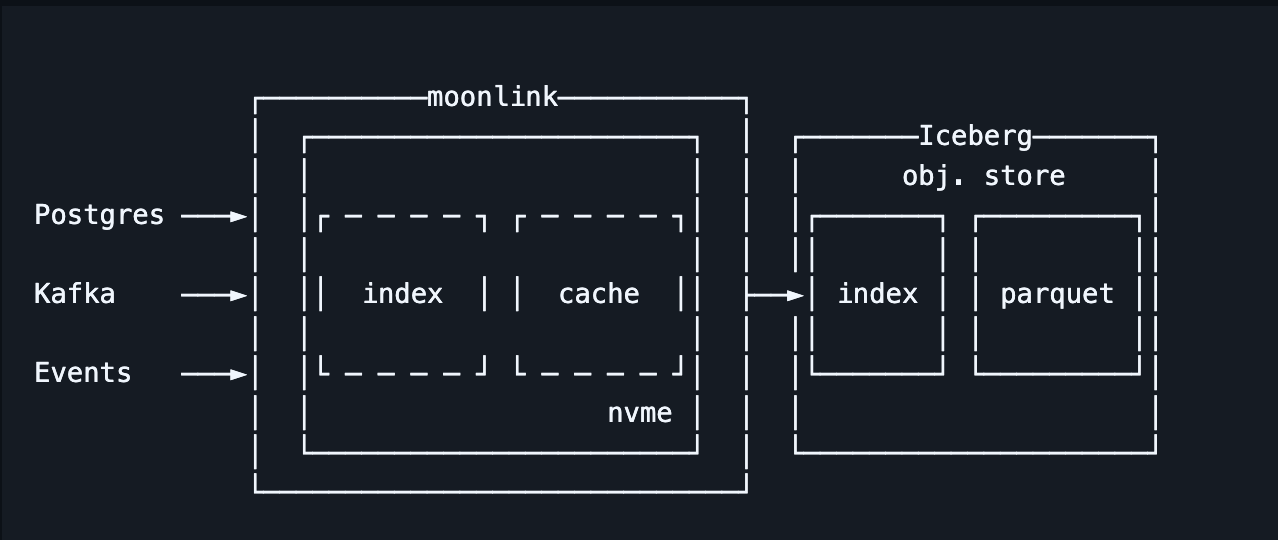
An alternative path for enabling real-time data modification in immutable data formats is to introduce a dedicated indexing layer, similar to those found in transactional databases, to manage row locations.
The core idea is to maintain an external index that maps each record's primary key to its precise location—the specific data file and row position. When an update or delete request arrives, the system first consults this index to find the existing record. It then generates a positional delete to invalidate the old row, inserts the new version of the row (in the case of an update), and finally updates the index with the new location.
To prevent the index from becoming stale, this architecture requires a metadata monitoring process. This process "tails" the commit log of the data table. When background operations like compaction rewrite data files, the monitor updates the index to reflect the new row positions.
The primary advantage is the ability to achieve real-time upserts directly within the data lakehouse, using highly efficient positional deletes that improve query performance by shifting the computational cost from readers to writers.
However, the challenges are significant. This pattern requires deploying, operating, and maintaining a separate, stateful indexing system. Keeping this index perfectly synchronized with the data is critical, as any lag or staleness, especially after compaction, can lead to data integrity issues. It introduces considerable operational complexity and another critical component into the data stack.
This approach shows that even Iceberg itself may evolve—not by abandoning immutability, but by augmenting it with real-time indexing.
DuckLake: A Transactional Approach to Lakehouse Metadata
DuckLake is a new open table format that re-architects the lakehouse by managing all metadata within a standard SQL database. It moves away from the complex file-based metadata systems of other formats. Instead, it leverages the transactional power and speed of a database to manage table versions, schemas, and file lists.
This design is particularly effective for handling fast-changing data, like a customer dimension table with frequent updates. When a record changes, the process is simple and efficient:
A new data file containing the updated row is written to object storage.
A single, atomic transaction is executed in the metadata database to commit the change. This instantly updates the table's state by pointing to the new data file.
By replacing slow, multi-file commits with fast database transactions, DuckLake can absorb high volumes of small, frequent updates without the performance degradation or metadata complexity seen in other formats. This approach simplifies the entire stack, providing the transactional speed needed for high-churn data workloads.
DuckLake illustrates another path: rethinking metadata management itself to unlock transactional speed for high-churn updates.
Conclusion
Fast-changing dimensions are no longer edge cases—they sit at the heart of personalization, fraud prevention, compliance, and real-time customer experience. They demand systems that can absorb high-velocity updates while preserving point-in-time accuracy.
Today, Iceberg meets this demand by offering equality deletes, positional deletes, merges, and medallion layers. These approaches work, but they impose trade-offs in cost, latency, and operational complexity. They reveal a deeper truth: the immutable-append model alone cannot carry the weight of FCD workloads.
The future will be hybrid. Iceberg will remain the backbone for historization and interoperability. Write-optimized systems like Hudi and Paimon could capture high-churn updates. External indexes and transactional approaches like DuckLake will push the boundaries of real-time upserts. Together, these innovations point toward a Lakehouse that blends mutability and immutability—architectures flexible enough to handle both yesterday’s facts and today’s changes.
In the end, managing fast-changing dimensions isn’t just a technical challenge. It’s a design principle for the next generation of data platforms: systems that evolve as quickly as the businesses they serve.
Given the size and activity level of the iceberg community (not to mention the effort to merge with delta lake), how long does everyone think it will take for them to these concerns? I know it doesn’t sound easy, but I’m reluctant to use HUDI, given people are seeming to move away from it.