
Data Engineering After AI
Moving Data Was Never the Point. Meaning It Is.

A few days back, I ran a LinkedIn poll asking what stays core to software engineering as AI increasingly writes the code. 53% said architecture and trade-offs. 20% said quality and ownership, and 25% said product and problem discovery.
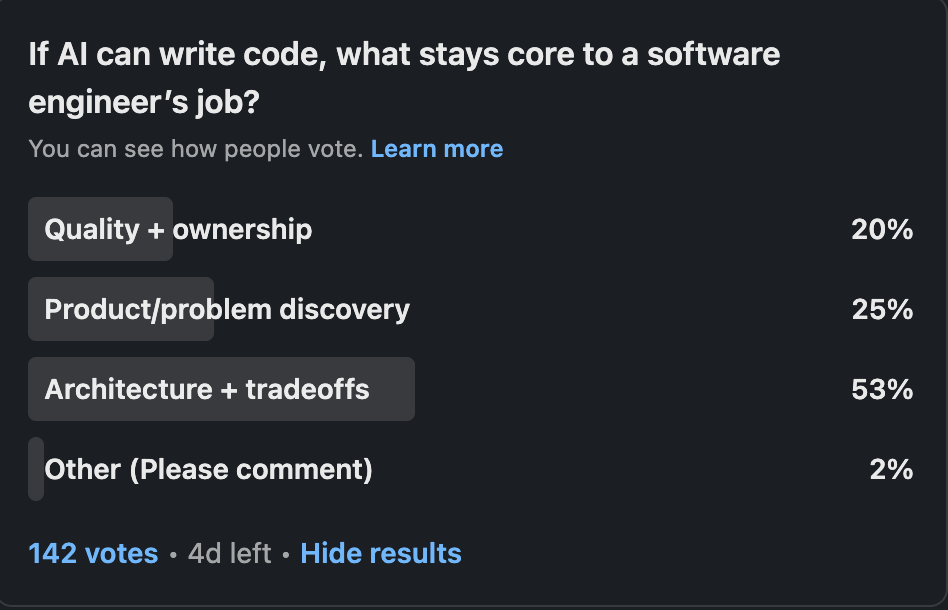
The poll wasn’t specifically about data engineering, but the answer it yielded applies directly to us. When AI can generate a pipeline as fluently as a senior engineer, the question isn’t whether our toolbox is changing — it clearly is. The question is: what kind of thinking has always been too important to automate, and why we let it get buried under the more mechanical work in the first place.
My answer is that the irreducible work was never about moving data. It was always about meaning. And the framework we’ve been using — ETL — was never really designed to capture meaning.
The ETL Era and Why It’s Ending
Extract, Transform, Load made sense as a job description for a specific historical moment. Source systems were siloed, formats were inconsistent, and somebody had to write the code that moved data from where it lived to where it could be used. The data engineer was that somebody.
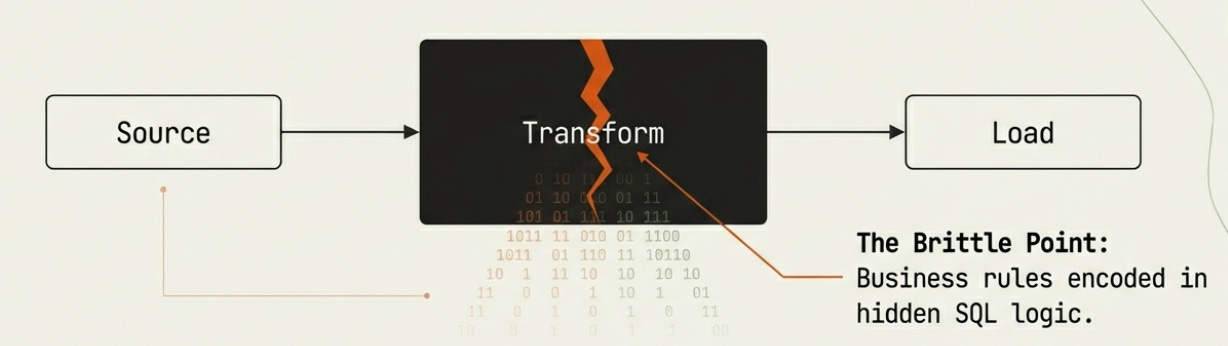
But if we’re honest, the transformation step was always the most brittle part. Teams encoded business rules as SQL logic or Python functions, buried them in pipeline code, version-controlled them alongside infrastructure, but rarely treated them with the same rigor as application code. When the definition of “active user” changed — and it always changed — someone had to find every place that definition lived and update it, hoping they caught them all.
AI is now competent at generating this kind of code. Not perfect, but competent enough that the mechanical work of pipeline construction is no longer a meaningful differentiator. If your professional identity is built around being good at writing transformation logic, that identity is under pressure.
But this isn’t a story about loss. It’s a story about clarity. The mechanical work was always obscuring the more important work underneath it. AI forcing that reckoning is, in a strange way, a gift.
Introducing ECL — Extract, Contextualize, Link
The framework emerging as a replacement isn’t a technical architecture so much as a reorientation of purpose. Instead of Extract, Transform, Load, think Extract, Contextualize, Link.

Extract remains. Data still needs to move from source systems to analytical environments, and that work still requires engineering judgment — about reliability, latency, volume, and failure modes. AI will increasingly handle the mechanical parts, but the architectural decisions about what to extract, when, and how belong to people who understand both the source systems and the downstream consequences.
Contextualize is where the real shift happens. This is the work of giving data semantic meaning — understanding that “revenue” is calculated differently by Finance and Sales, that a timestamp in a clickstream event means something different than a timestamp in a billing record, that a null value in one system represents the absence of information while in another it represents an explicit user choice. AI can draft this work at scale — inferring field definitions, classifying entities, and mapping relationships across a data landscape that no human team could manually annotate in full. What AI cannot do is be accountable for itself. The judgment of whether an inference is correct, the organizational authority to declare a definition, the decision to formalize a discovered pattern into an enforced contract — that belongs to humans. Contextualize is where AI inference and human judgment meet, structured by a pipeline built specifically for that purpose.
Link is about entity relationships across the data landscape — connecting a customer record in your CRM to a user record in your product database, linking an event in your analytics system to a session in your support tool. As AI generates more of the code that consumes data, the ability to reason about how entities relate across systems becomes more valuable, not less. Linkage is what makes context portable — what allows the meaning built in one part of the landscape to be grounded in its relationships to the rest.
The rest of this article discusses how ECL works at the architectural level, not as three abstract concepts, but as three concrete pipelines — and why you need all of them.
Early Binding — Contracts as Executable Constraints
The first technique is early binding: capturing semantic intent at the point of data production, before the data moves.
Data contracts are the practical implementation of this idea. At their core, contracts are agreements between data producers and their consumers — specifying schema, data quality expectations, ownership, and the semantic meaning of each field.

Data Engineering Weekly identified this gap precisely in their piece Data Contracts: A Missed Opportunity. While the data industry was debating what contracts were and drafting governance frameworks to describe them, software engineering had quietly converged on a different organizing principle: treating specifications as executable constraints with real failure semantics. The data industry treated contracts as documentation. Software engineers treated them as interfaces — things that could break, that had versioning implications, that enforced behavior rather than merely describing it.
A data contract that lives in a wiki and gets updated when someone remembers is the documentation. A data contract that is enforced at the point of production — that fails a pipeline when a schema changes without notice, that alerts a consumer when quality thresholds are violated, that an AI agent can reason about deterministically — that is architecture.
This matters more in an AI-heavy world, not less. When AI agents generate transformation code, bad contracts are amplified at scale. The agent will faithfully implement whatever logic it’s given; if the contract governing its inputs is ambiguous or unenforced, the errors it produces will be systematic rather than isolated. Early binding is the mechanism by which human intent gets formalized into something AI can actually work with.
But early binding alone has a fundamental limitation. And understanding that limitation is what makes the Contextualize pipeline necessary.
The Problem Early Binding Alone Can’t Solve
Consider what happens to a well-contracted dataset as it moves through a modern Medallion architecture.
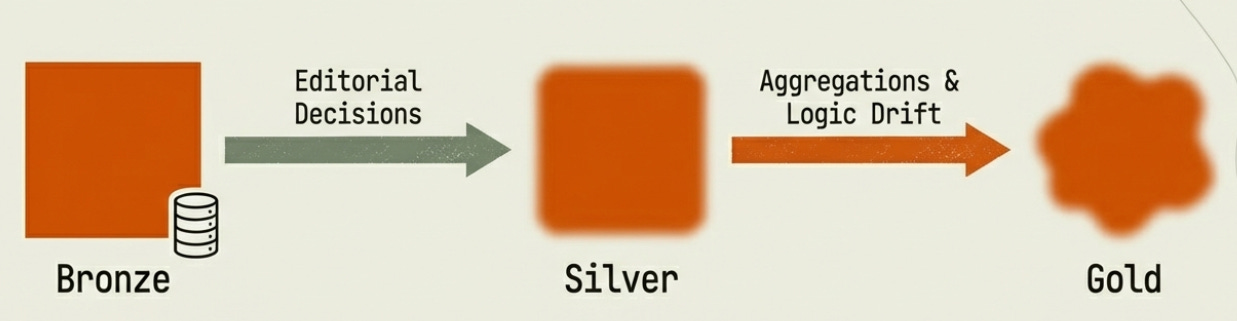
At the Bronze layer, data lands close to its source — raw, minimally transformed, the contract’s guarantees still largely intact. Silver applies conformance rules: deduplication, type casting, and light standardization. By the time data reaches Gold, the pipeline has made a series of editorial decisions on the data’s behalf. Aggregations collapse granular events into metrics. Engineers bake business logic into the shape of the table. The Gold layer is an artifact optimized for a specific set of questions — the ones that seemed important when the pipeline was built.
Early binding contracts help at the source, but they can’t prevent this erosion at every subsequent hop — especially when those contracts are treated as descriptive rather than executable. If there’s no enforcement mechanism preventing meaning from drifting across transformations, the telephone game plays out silently in your pipeline. By the time a consumer queries the Gold layer, they’re working with an artifact whose original intent may be several editorial decisions removed from the contract.
This is the problem that early binding alone cannot solve. Each transformation layer progressively collapses the context captured at the source. You need a complementary approach—one that preserves the ability to recover context when it’s actually needed.
Late Binding — The Agentic Contextualized Pipeline
Traditional late binding deferred the application of business rules to query time. What it didn’t defer was the definition of those rules — domain experts still had to specify them upfront, just applied through a semantic layer rather than baked into a physical table. In complex domains, that knowledge engineering process was its own bottleneck.
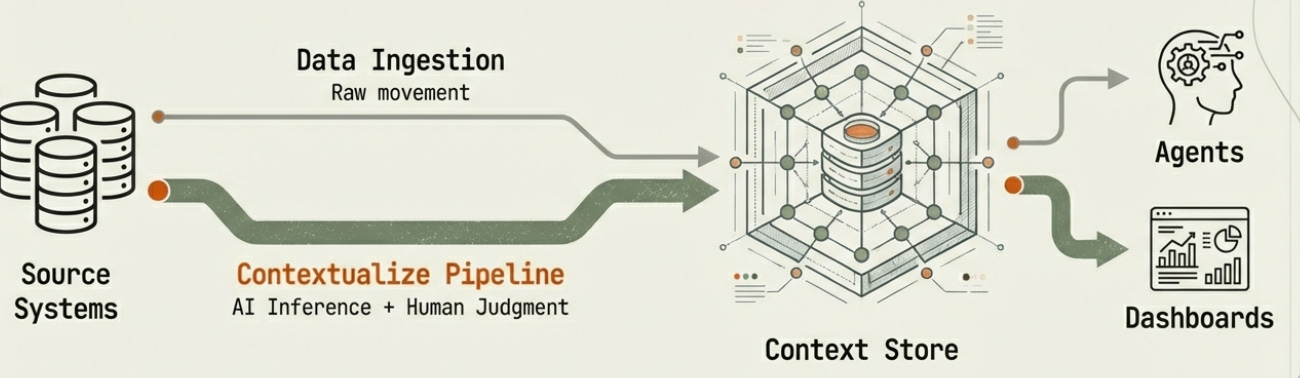
The more forward-looking approach is to defer definition itself — and hand that work to a dedicated pipeline.
The Contextualize pipeline is a separate, agentic pipeline that runs alongside your data infrastructure. Its job is singular: build and maintain a living, validated store of semantic context. It isn’t part of the Extract pipeline. It isn’t a query-time process. It’s a first-class engineering artifact with its own triggering model, validation layer, and storage.
The trigger is event-driven, not scheduled. Every new dataset that lands automatically kicks off the pipeline. For existing datasets, continuous profiling monitors for meaningful changes — a new column appears, a column is dropped, a data distribution shifts in ways that suggest something changed upstream. Any of these events re-triggers the pipeline for the affected entities. Semantic context isn’t a one-time annotation exercise. It tracks the data as it evolves.
The pipeline itself is agentic. An AI agent analyzes the incoming data — schema, sample values, statistical profiles, lineage — and infers semantic meaning. What does this field represent? What business entity does it belong to? What relationships exist between it and other data in the landscape? It produces structured, versioned context artifacts: inferences about meaning that didn’t require a domain expert to pre-specify every scenario.
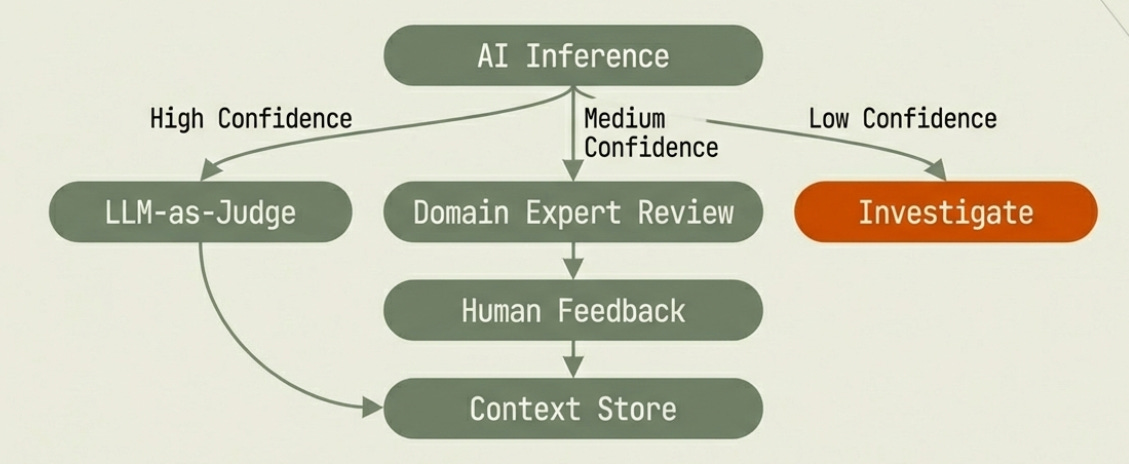
Those inferences don’t automatically commit. They route to a validation layer that works like a labeling workflow — because structurally, it is one. An LLM-as-Judge validates high-confidence inferences before any human review triggers. Medium-confidence ones surface to domain experts for labeling. The pipeline flags low-confidence or contested inferences for deeper investigation. The humans aren’t reviewing every artifact; they’re reviewing the uncertain ones. Every labeling automation technique that works in ML pipelines applies here.
Validated artifacts land in a Context Store — a dedicated, versioned, queryable store of semantic definitions, entity classifications, and relationship maps. This is the new infrastructure component that ECL requires. Downstream agents don’t query raw data and infer meaning on the fly. They query the Context Store first, ground their understanding in validated context, and then query the data. The context is stable, reusable, and auditable — the opposite of ephemeral query-time inference.
Early Binding vs Late Binding — When to Choose What
The decision criterion isn’t about semantic maturity or how well-understood a domain is. It’s about where the data comes from relative to your accountability boundary.
When a dataset originates within a controlled environment — produced by a team or system within your organization’s sphere of accountability — early binding is the right tool. The producer and consumer share an organizational context. Contracts can be negotiated, enforced, and held to. The producing team can be made accountable for the schema they declare and the semantics they commit to. Prescribed context is possible because the relationship that makes it enforceable exists.
When a dataset originates outside that boundary — third-party feeds, partner data, public datasets, marketplace sources — that relationship doesn’t exist. You cannot hold an external provider to a data contract. The schema can change without notice. The semantics are inferred, not declared. This is where the Contextualize pipeline earns its place. Discovered context is the only kind available.
But the boundary is not purely organizational. Poorly governed internal data — produced by a team with no accountability to its consumers, with undocumented schemas and inconsistent definitions — is effectively uncontrolled even if it sits within the same organization. The real test is not position on an org chart. It is accountability. Early bind where accountability exists. Let the Contextualize pipeline discover where it doesn’t.
The feedback loop holds in both directions. Discovered context built up through repeated profiling, inference, and validation can graduate into a prescribed context over time. An external dataset that your organization ingests consistently enough to profile, validate, and republish as an internal data product crosses the boundary from uncontrolled to controlled at that point. The Contextualize pipeline is what makes that transition possible — and makes the resulting contract trustworthy rather than assumed.
A data environment that treats all data as early-bindable is brittle. It can only contract what it already understands, and it has no mechanism for the uncontrolled data that makes up a growing share of the analytical landscape. A data environment that treats all data as requiring discovery never formalizes what it learns into enforceable guarantees. The architecture that works reads the accountability boundary correctly and applies the right technique on both sides.
Context Propagation — The Relay, Not the Pipeline
With three pipelines now in play, the question becomes: how does context actually travel through the architecture without getting lost?
The conventional mental model is wrong. Context doesn’t travel through the data pipeline—if it did, it would be lost at every transformation step, which is precisely the Medallion erosion problem. Context travels alongside the pipeline, as metadata, lineage records, and contract provenance. The transformations change the data; the metadata preserves the meaning.
The relay works like this. Early binding stamps prescribed context at the point of origin — schema, field-level semantics, producing team ownership, quality thresholds — as an executable contract living in metadata, not column values. Lineage tooling propagates this through Bronze, Silver, and Gold, maintaining a record of the transformations applied and the contract that governed the data at each stage. The Contextualize pipeline reads that lineage as part of its inference process — understanding not just what a field looks like today, but also the history of how it arrived and the commitments made about it at the source. Validated inferences land in the Context Store, which becomes the relay’s destination: a durable, queryable record of what the data means, grounded in both original contract and accumulated lineage.
The analogy that makes this concrete is git. A file can be modified heavily across dozens of commits — refactored, renamed, moved, rewritten — but the context of how it got there is never lost, because it lives in the commit history, not in the file itself. The Gold layer is the latest commit. The lineage graph is the git log. The Context Store is the understanding you build by reading that log systematically rather than hoping the current file tells the whole story.
This reframe — from pipeline to relay — changes what data engineers are actually responsible for building. The transformations are increasingly automatable. The metadata infrastructure, the lineage graph, the Contextualize pipeline that reads it, the Context Store that accumulates from it — that is the engineering surface that requires sustained human judgment.
The Context Store as the New Engineering Surface
Which brings us to where the most consequential engineering work has migrated.
The Context Store is where business definitions live — not as documentation in a wiki, not as logic engineers have baked into a Gold table, but as versioned, validated artifacts that downstream systems can query and trust. This is where the validation workflow resolves the competing interpretations of “revenue” from Finance and Sales — not organizational politics, but a confidence-based process that determines which inference earns formalization. Where AI consumers find the grounded, stable context they need to act reliably rather than reverting to ad hoc inference.
This surface distinguishes queryable data from trustworthy data. A table can be perfectly partitioned, indexed, and replicated while being semantically wrong — built on a definition that drifted from its source contract three transformations ago and never caught because no Contextualize pipeline was watching. The Context Store is where that failure mode gets closed.
As AI generates more transformation code and AI agents consume more data at scale, the stakes of this surface rise. An agent operating on a stale or conflicting context artifact produces systematic errors rather than recoverable ones. The engineering work that governs trustworthiness — designing the trigger model for the Contextualize pipeline, structuring the labeling workflow, deciding what validation confidence threshold earns formalization, and versioning context artifacts as definitions evolve — requires human judgment at every step.
Practitioners are still working out the patterns for doing this at scale. The tooling is maturing. How organizations govern ownership of the Context Store, adjudicate conflicts between teams, and manage the graduation from discovered to prescribed context are genuinely open questions. This is where the frontier actually is.
The New Data Engineer — Context Architect
Return to the poll. 53% said architecture and trade-offs are what remain irreducibly human. In the data engineering context, ECL is what that looks like in practice.

The data engineer of the next decade owns the architecture of meaning. They design the contractual foundations at the source—executable, enforceable, versioned. They build the lineage infrastructure that carries context through every transformation layer without losing it. They design and govern the Contextualize pipeline and the Context Store — the infrastructure where inferences get built, validated, and formalized into the definitions that everything downstream depends on. They understand when to prescribe context upfront and when to let it be discovered, and they build the systems that make both possible.
But this is not only a technical role. Context erosion is as much an organizational failure as a technical one. Teams don’t share semantic definitions because no ownership model incentivizes them to do so. Nobody enforces contracts because producing teams have no accountability to the consumers they serve. In this new frame, the data engineer is the person who builds both the technical system and the organizational agreement that holds it together. They sit at the intersection of architecture and coordination — the two things the poll respondents correctly identified as irreducibly human.
The title “Data Engineer” may need an update. What we are actually describing is a Context Architect — someone whose primary material is not data movement but data meaning, not pipelines but provenance, not transformation logic but the semantic infrastructure that makes transformation logic trustworthy.
An Open Frontier
I want to be honest about what ECL is and what it isn’t. It is a reorientation — a way of thinking about what the work actually is, now that AI is handling more of what the work used to look like. It is not a finished methodology. The tooling that links early binding contracts to the Contextualize pipeline and Context Store is still maturing. The organizational patterns for governing who owns the Context Store, how conflicts between teams get adjudicated, and how discovered context earns formalization don’t yet have established templates. Practitioners are working out the engineering patterns for building contextual pipelines that operate reliably at scale in production environments right now, figuring it out as they go.
That’s precisely what makes this moment worth paying close attention to. The frontier is genuinely open. The practitioners who invest in the architectural and organizational work of context — who treat contracts as executable infrastructure, who build lineage as a first-class engineering concern, who govern the Contextualize pipeline and Context Store as seriously as they once owned the ETL pipeline — will define the discipline for the decade ahead.
The 53% who said architecture and trade-offs are irreducibly human were right. We didn’t yet know which architecture, or which trade-offs.
Now we do.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Enjoyed this blog and love the direction. But I still see the ownership problem — someone still needs to validate the Context Store, and it's the same domain experts who won't own their data today.
The most valuable business context lives in people's heads, not in schemas or data profiles. In the SAP world, a field like PRCTR behaves differently across company codes. Certain document types in ACDOCA need to be excluded for specific reporting scenarios. That knowledge is tacit — it came from years of working with the system, not from profiling the data. How do you capture that in a contract or a schema?
This is going to be very challenging, and I'd love to see how AI evolves to solve it.
I like where you are taking the Data Engineering discussion! Organizations need to recognize the value of managing context and that its new to many running projects required data pipelines. Getting specifications right will also be important as we employ coding agents as first class engineers. And as for spec-driven-development stuff... like everything else in this new era of engineering it's getting redesigned as well!
Also, see https://ai.bythebay.io/talks/spec-driven-development