
Data Engineering Weekly #190
The Weekly Data Engineering Newsletter

Editor’s Note: Coming Next on Comparison Matrix Series - Data LakeHouse
Our mission is to empower data professionals and organizations to make informed, data-driven decisions by providing a comprehensive buyer's guide and comparison matrix for selecting the best data tools. We have already published a comparison matrix for CDC and Data Observability. Next, we will publish a comparison matrix for LakeHouse.
All the comparison matrix builds upon collective interactive sessions with the Data Heros community. Please watch the community LinkedIn page, where we will post the link for the discussion.
We won't record this conversation in the true spirit of community and open knowledge-sharing.
Uber: QueryGPT – Natural Language to SQL Using Generative AI
Companies are increasingly adopting the natural language interface to interact with the enterprise data.
I’m fairly confident that a framework that supports a deterministic way of building a data pipeline and a conversational way of building business logic is the future of data pipeline engineering.

Uber writes about its journey in building the natural query interface for the data warehouse, including the lessons learned from the first iteration and the adoption of the multi-agent approach to tuning accuracy.
https://www.uber.com/blog/query-gpt/
Dropbox: How we use Lakera Guard to secure our LLMs
As the adoption of LLM increases, prompt injection, hallucination, and other security & compliance guards are required to secure the application. Dropbox writes a case study on integrating Lakera Guard into their prompt engineering to secure the LLM infrastructure.
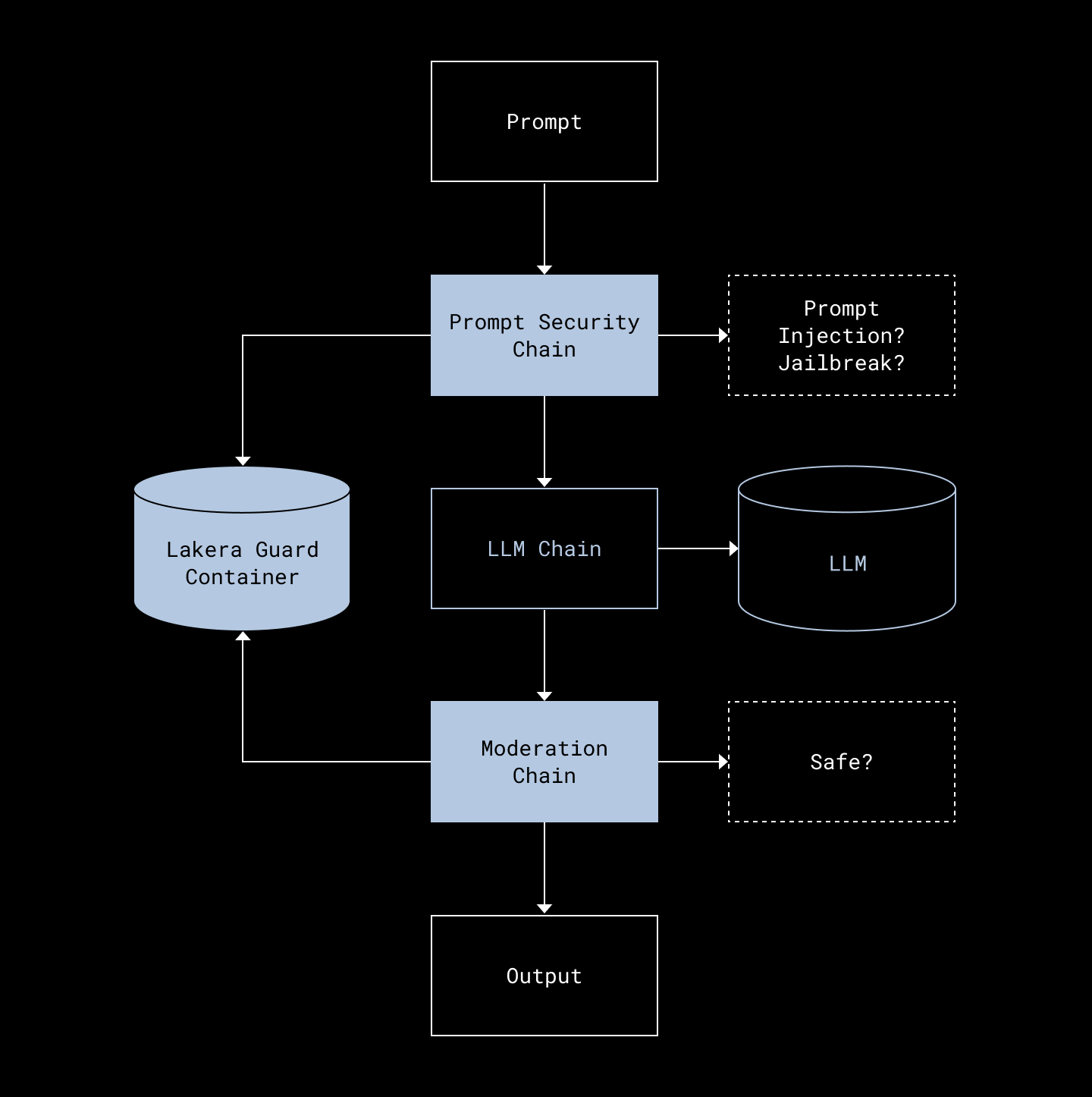
https://dropbox.tech/security/how-we-use-lakera-guard-to-secure-our-llms
Flipkart: Flipkart Enhances AI Safety in E-Commerce - Implementing NVIDIA NeMo Guardrails
Flipkart is leveraging NVIDIA's NeMo Guardrails to strengthen AI safety in its e-commerce platform, ensuring compliance and safeguarding customer interactions. This move demonstrates the growing importance of AI governance in real-world applications, especially as data-driven businesses like Flipkart scale their machine-learning operations. This highlights a crucial trend for data engineers: AI safety mechanisms are becoming an integral part of ML pipelines, reinforcing the need for robust monitoring and control frameworks in the data ecosystem.
Sponsored: IMPACT - Have you seen the agenda for IMPACT: The Data Observability Summit yet?
This year's core theme is Trusted Data & AI, and two core breakout tracks will feature industry leaders in the data space!
The Leading with Trusted Data & AI track is designed for innovative data leaders in the age of AI. It features sessions from visionaries pioneering the future of data at Pepsi, ZoomInfo, Drata, Roche, and more.
The Pioneering Data Observability track is comprised of sessions led by data practitioners from leading data teams at Payoneer, Earnest, SurveyMonkey, Grammarly, and DraftKings, who will share their tech, frameworks, and strategies for scaling data observability to build trusted data, systems, and code.
No matter where you sit in your organization, you won't miss the opportunity to learn from industry leaders and gain valuable insights into what's in store for the future of trusted data and AI. Register today:
Thomson Reuters Labs: Better Customer Support Using Retrieval-Augmented Generation (RAG) at Thomson Reuters
Thomson Reuters enhances customer support by using Retrieval-Augmented Generation (RAG), which integrates large language models with real-time information retrieval. The combination allows customer service teams to provide accurate and context-aware responses by pulling up-to-date information from company resources. The key takeaway is that RAG adoption is increasing, and that shows in the improved quality and relevance of automated responses, making customer interactions more efficient and effective.
Grab: LLM-powered data classification for data entities at scale.

Grab has implemented a powerful solution for data classification by leveraging large language models (LLMs) to tag and categorize their data automatically. Traditionally, this task was labor-intensive and prone to inconsistencies. By integrating LLMs, Grab streamlined the classification process, allowing the system to efficiently generate column-level tags for sensitive data and business metrics. The LLM-powered approach improves accuracy and speed, providing a more scalable way to manage metadata for their diverse and rapidly growing data.
https://engineering.grab.com/llm-powered-data-classification
Wix: Customizing LLMs for Enterprise Data Using Domain Adaptation: The Wix Journey
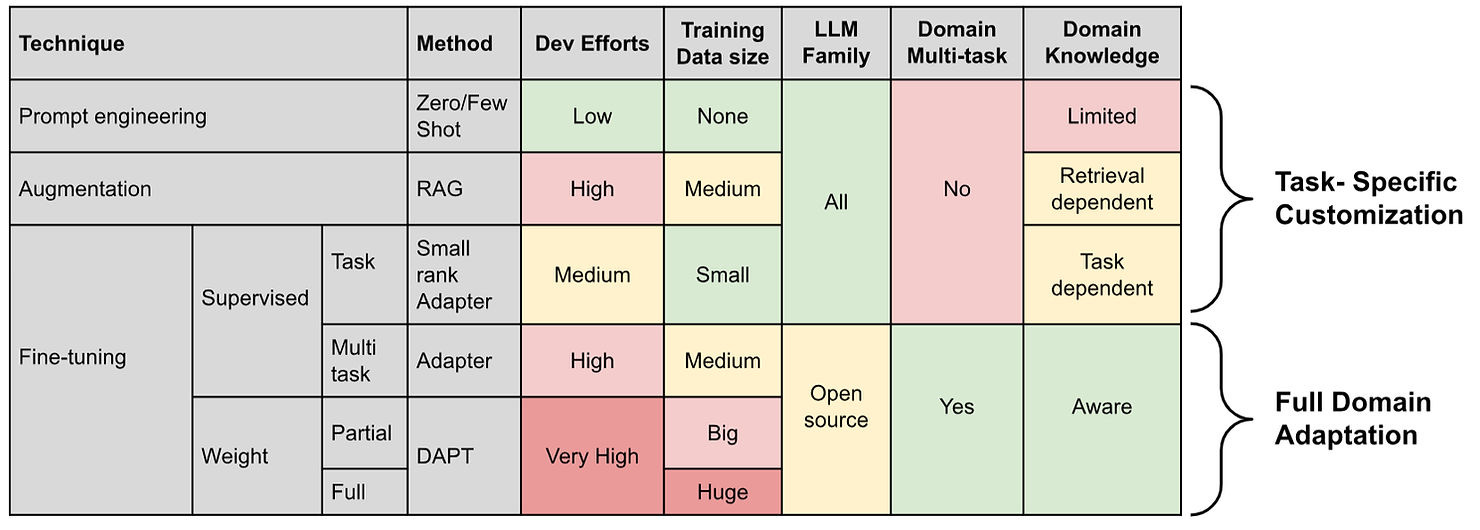
The logical next step for enterprises to adopt LLM is to train the model with domain-specific data. Wix writes about customizing large language models (LLMs) for enterprise data using domain adaptation techniques. This process allows them to fine-tune LLMs to better understand and respond to their specific data, enhancing performance for tasks like customer service and internal operations.
Pinterest: Pinterest Tiered Storage for Apache Kafka®️: A Broker-Decoupled Approach

Decoupling the storage from the compute/ brokers significantly reduces the total cost of ownership. We see this trend in stream processing systems. Pinterest writes about its adoption of tiered storage for Apache Kafka. The system handles large-scale data by offloading older, less frequently accessed data to cheaper storage tiers while keeping active data on high-performance storage.
Brittany: Lessons from Human Data Analysts to Improve the AI Variety
Can AI replace human data analysts? The author shares a perspective on how human analysts can potentially use AI. The author emphasizes that human intuition, experience, and contextual understanding are key to making sense of complex data beyond what automated tools can achieve but states the importance of combining human expertise with AI data tools to foster better collaboration between business teams and data analysts.
https://datafordoers.substack.com/p/lessons-from-human-data-analysts
Yuno: How Apache Hudi transformed Yuno’s Data Lake
 environment.")
Yuno writes about transforming its data infrastructure by implementing Apache Hudi, optimizing data lake performance, and reducing costs by 70%. Hudi's features, such as time travel, indexing, and automated file management, enabled real-time data insights and improved efficiency. Yuno utilized Hudi’s flexibility across different use cases and integrated it with AWS Glue and Airflow for orchestration.
https://www.y.uno/post/how-apache-hudi-transformed-yunos-data-lake
HomeToGo: HomeToGo’s North Star Metric for our Data Domain

Can you measure the effectiveness of your data ecosystem? The HomeToGo team writes about a set of "North Star Metrics" to align its data domain efforts with business objectives. The metrics are a guiding measure to track the performance and impact of data initiatives across the organization. The key takeaway is that having a clear, measurable objective allows teams to maintain focus and ensure their work contributes directly to the company's overall goals.
https://engineering.hometogo.com/hometogos-north-star-metric-for-our-data-domain-7f0f5fb96e30
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.