
Data Engineering Weekly #211
The Weekly Data Engineering Newsletter

Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA
Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. As a special perk for Data Engineering Weekly subscribers, you can use the code dataeng20 for an exclusive 20% discount on tickets!
https://www.datacouncil.ai/bay-2025
Tell us about your Lakehouse Stack
In the last two episodes of Data Engineering Weekly, we discussed the current state of Lakehouse. I’m curious to know your organizational strategy for Lakehouse.
Gradient Flow: DeepSeek Fire-Flyer: What You Need to Know

DeepSeek's Fire-Flyer (FF) is a classic example of resource constraint. It combines system design innovations with cost-effective, high-performance AI-HPC infrastructure for large-scale AI model training and inference. The blog details DeepSeek's motivations for building FF (addressing cost, scalability, and AI-specific optimization), outlines FF's limitations (PCIe bandwidth, NVLink issues), and discusses implications for AI teams (democratization, cost-efficiency, hardware-software integration).
https://gradientflow.com/deepseek-fire-flyer/
Maya Murad: Hard-Earned Lessons from a Year of Building AI Agents
The article details the author's journey in developing AI agents, starting with early observations about LLMs' problem-solving capabilities and the challenges non-experts face in using them. The blog highlights the iterative process, including prototyping an agent with a visual trajectory explorer, open-sourcing the BeeAI framework, and learning from user feedback. The article emphasizes the importance of developer experience, flexible agent architectures, innovative interaction modalities, and rigorous evaluation.
https://medium.com/@mayamurad/hard-earned-lessons-from-a-year-of-building-ai-agents-945d90c78707
Alibaba: Development Trends and Open Source Technology Practices of AI Agents
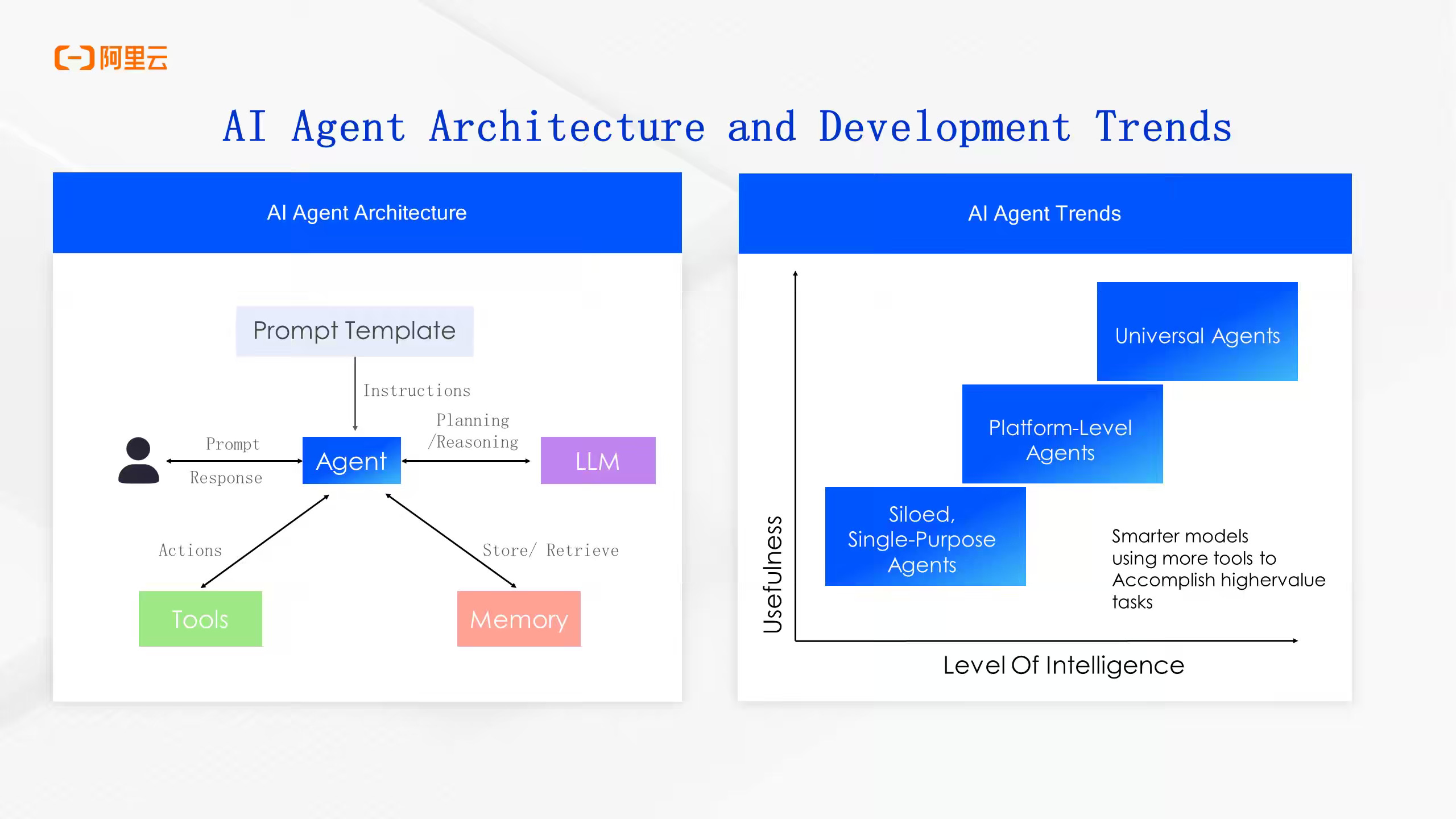
Agent building is one of the fast-moving software engineering disciplines. Alibaba writes about the evolution and development trends of AI Agents, emphasizing the shift from single-agent to multi-agent systems and the importance of data-centric platforms. The blog highlights Alibaba's approach to building AI agent competitiveness through models, data, and scenarios. It focuses on private data and high-frequency, structured use cases, introduces a "data flywheel" for continuous improvement, and presents a data-centric intelligent agent architecture.
Vinoth Chandar: 21 Unique Reasons Why Apache Hudi Should Be Your Next Data Lakehouse
One of DEW’s predictions is the lakehouse systems will absorb typical database functionalities as they grow. We called it LakeDB in the prediction. It is exciting to see Apache Hudi increasingly moving towards it with secondary index support, built-in table services, etc. Apache Hudi’s adoption is reassuring for the LakeDB prediction.

https://hudi.apache.org/blog/2025/03/05/hudi-21-unique-differentiators/
Gojek: Every Impression Counts: How the Ads Team Supercharged Gojek’s Telemetry Event Collection
Gojek's Ads engineering team writes about its telemetry event collection, focusing on accurate impression counting and data reliability. The blog highlights the implementation of HyperLogLog (HLL) for efficient and precise counting of unique ad impressions, reducing load and improving memory efficiency by ~50%. It also introduces a parallel telemetry system using Gojek's Courier (MQTT-based) to verify and identify gaps in their existing system.

Grab: Building a Spark observability product with StarRocks: Real-time and historical performance analysis.
Grab describes enhancing their Spark observability tool, Iris, by migrating from a Telegraf/InfluxDB/Grafana (TIG) stack to a StarRocks-based architecture. The system design provides a unified platform for real-time and historical data, streamlines data ingestion directly from Kafka, uses materialized views for faster query performance, and offers a custom web application (Iris UI) for improved user experience, enabling them to make better-informed decisions. The article also details the data model, ingestion process, query optimization strategies, and plans.
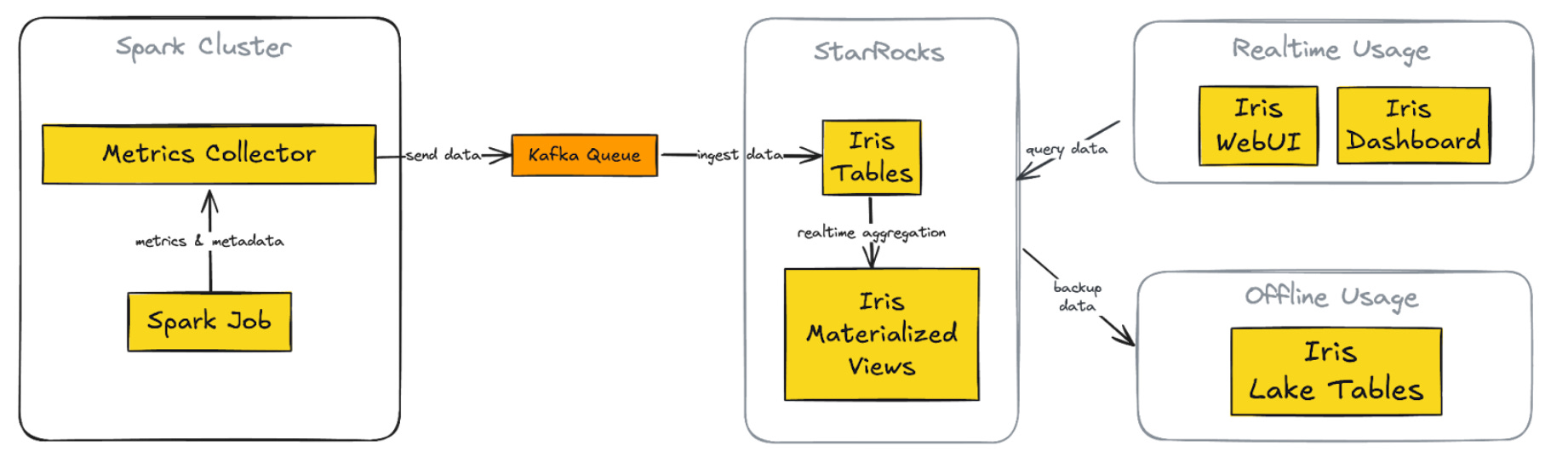
https://engineering.grab.com/building-a-spark-observability
Halodoc: Schema Change Management at Halodoc
Halodoc writes about its in-house schema change management framework using Apache Hudi, PySpark, and AWS Glue Data Catalog. Glue Data Catalog limitations and a need for more control, Halodoc writes a framework to handle schema changes (column additions, deletions, and data type changes) by comparing schemas, updating configurations, and processing data, saving up to 15 hours per month by automation.

https://blogs.halodoc.io/schema-change-management-at-halodoc/
Slack: How we built enterprise search to be secure and private
Enriching a model context with enterprise data without compromising security and privacy will be an interesting system design challenge. Claude recently released MCP to do the same. Slack publishes a similar system design that extends the Slack app ecosystem to access enterprise data in a secure, zero-copy design.

https://slack.engineering/how-we-built-enterprise-search-to-be-secure-and-private/
AWS: Express brokers for Amazon MSK: Turbo-charged Kafka scaling with up to 20 times faster performance
Kafka replication is the most reliable protocol implementation; however, it also saturates the consumer throughput. Adding and removing a broker is a challenge in itself. Traditional Kafka brokers store data locally on attached storage volumes, which can lead to availability and resiliency issues. MSK Express brokers, however, offer fully managed and highly available Regional Kafka storage, decoupling compute and storage resources. I like this design better than the S3-based Kafka protocol.

All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.