
Data Engineering Weekly #221
The Weekly Data Engineering Newsletter


Dagster Components is now here
Components provides a modular architecture that enables data practitioners to self-serve while maintaining engineering quality. Built for the AI era, Components offers compartmentalized code units with proper guardrails that prevent "AI slop" while supporting code generation.
See how it works in 4 easy steps
Onehouse: ClickHouse vs StarRocks vs Presto vs Trino vs Apache Spark™ — Comparing Analytics Engines

As we adopt the Lakehouse architecture more and more, the quest for a robust query engine increases. I think the market is wide open for more innovations, as Onehouse announces a compute runtime named Quanton. The blog is an excellent compilation of types of query engines on top of the lakehouse, its internal architecture, and benchmarking against various categories.
Gunnar Morling: What If We Could Rebuild Kafka From Scratch?
KIP-1150 ("Diskless Kafka") is one of my most anticipated releases from Apache Kafka. Outsourcing the replication of Kafka will simplify the overall application layer, and the author narrates what Kafka would be like if we had to develop a durable cloud-native event log from scratch.
https://www.morling.dev/blog/what-if-we-could-rebuild-kafka-from-scratch/
Rentry: Dummy's Guide to Modern LLM Sampling

The article provides a comprehensive guide to modern Large Language Model (LLM) sampling techniques, explaining why sub-word tokenization (using methods like Byte Pair Encoding or SentencePiece) is preferred over letter or whole-word tokenization. The blog details how LLMs generate text by predicting the next tokens based on learned probabilities and then dives into various sampling methods that introduce controlled randomness to make outputs more varied and creative.
Sponsored: The Data Platform Fundamentals Guide

A comprehensive guide for data platform owners looking to build a stable and scalable data platform, starting with the fundamentals:
- Architecting Your Data Platform
- Design Patterns and Tools
- Observability
- Data Quality
Adrian Brudaru: The shift to Grey Box Engineering and Outcome Engineering
Grey Box Paradigm: You assess quality through outcomes, not through code review
The nature of data engineering is an iterative process of the grey box paradigm. If you look at all the BI or UI-based ETL tools, the code is a black box for us, but we validate the outcome generated by the black-box. Understanding this fact will help data tools break new ground with the advancement of AI agents.
https://dlthub.com/blog/grey-box
SquareSpace: Leveraging Change Data Capture For Database Migrations At Scale
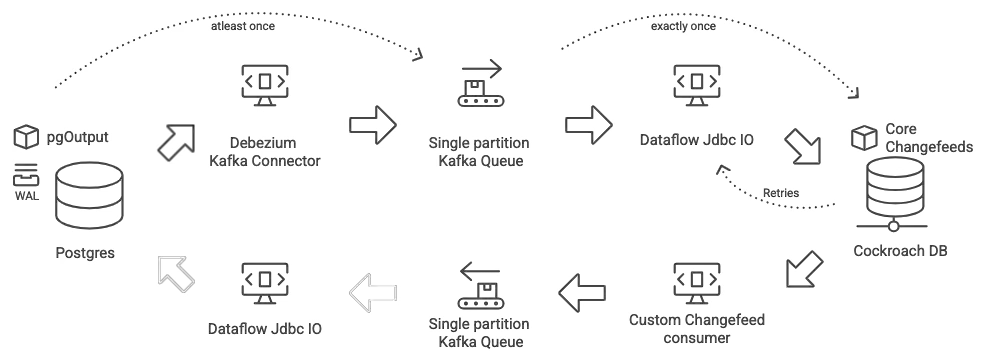
Squarespace writes about migrating their business-critical PostgreSQL databases to CockroachDB (CRDB) at scale. The migration strategy involved using PostgreSQL's Change Data Capture (CDC) capabilities (specifically pgoutput and Debezium with Kafka Connect) to stream real-time data changes (inserts, updates, deletes) in Avro format to Kafka topics. Then, a custom Apache Beam consumer processed these events, transforming and writing them to CRDB.
Pinterest: 500X Scalability of Experiment Metric Computing with Unified Dynamic Framework

Pinterest writes about the Unified Dynamic Framework (UDF), a scalable, resilient solution that has transformed experiment metrics computation. The experimentation pipeline is always the hardest one since it usually runs last after computing critical metrics. Pinterest talks about a unified metric computing framework leveraging Airflow’s dynamic DAG and a metric registry to overcome the inefficiencies in metric computations.
Yudhiesh Ravindranath: The Achilles Heel of Vector Search: Filters
The article explores the performance challenges of applying filters to Approximate Nearest Neighbor (ANN) vector search, often slowing it down, unlike traditional database filtering, and examines three main strategies:
pre-filtering (filter-then-search, which can degrade to brute force)
post-filtering (search-then-filter, risking missed results or high latency with restrictive filters)
In-algorithm filtering (integrated approaches by Qdrant, Weaviate, and Pinecone).
The author highlights benchmark results showing that engines with integrated filtering often improve throughput and maintain low latency with filters.
https://yudhiesh.github.io/2025/05/09/the-achilles-heel-of-vector-search-filters.html
Vimeo: Behind Viewer Retention Analytics at Scale
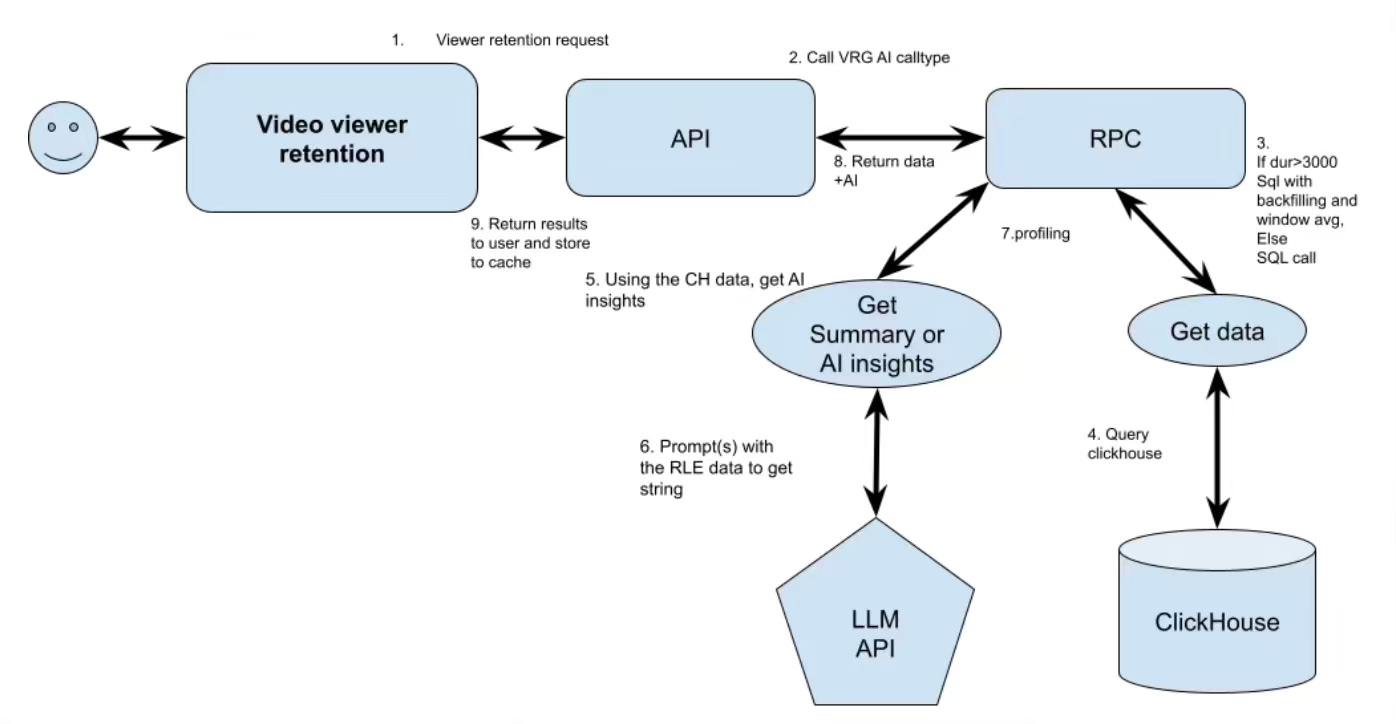
Vimeo outlines its architecture for delivering viewer retention analytics at scale, leveraging ClickHouse and AI to process data from over a billion videos. Vimeo captures granular viewer actions (skips, repeats, scrubs) by logging changes in views per second (+1 for start, -1 for end) and stores these in an AggregatingMergeTree table in ClickHouse, enabling efficient real-time aggregation. To provide AI-driven insights, Vimeo preprocesses retention data (window averaging, Run-Length Encoding) to minimize tokens and uses structured prompt engineering for LLMs (Gemini Flash 2.0 and Lite 2.0) to pinpoint drop-offs and high retention sections.
https://medium.com/vimeo-engineering-blog/behind-viewer-retention-analytics-at-scale-8dbbb5ae7ae2
Yuval Yogev: Making Sense of Apache Iceberg Statistics
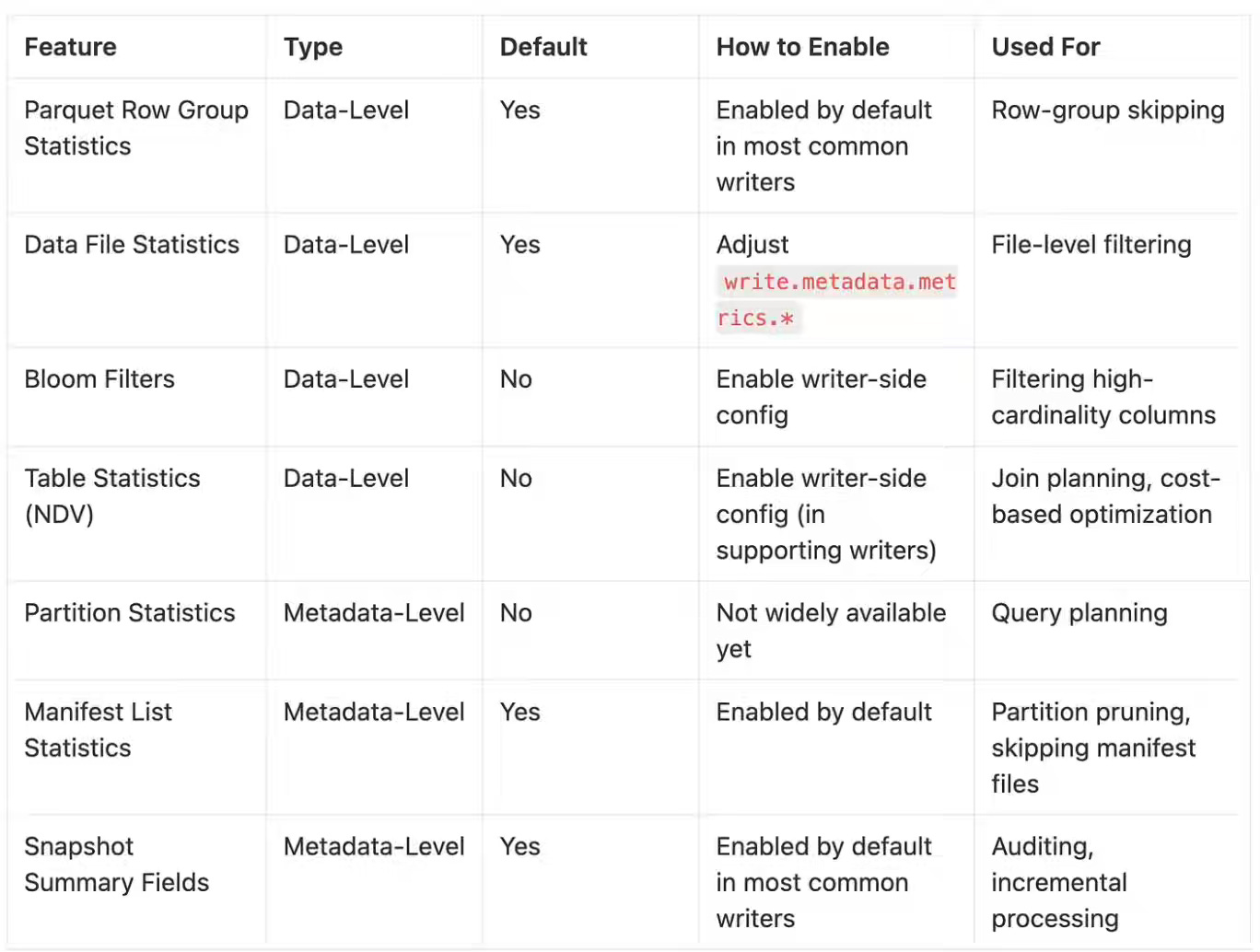
A rich metadata model is vital to improve query efficiency. The author did an excellent job of summarizing the levels of metadata collected by Iceberg, how to enable it, and what it is used for.
https://medium.com/@yogevyuval/making-sense-of-apache-iceberg-statistics-5a114d8e90d1
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.