
Data Engineering Weekly #222
The Weekly Data Engineering Newsletter


Dagster for MLOps: Deep Dive into AI Orchestration
Learn what it really takes to run production-grade ML systems—without breaking your architecture or compliance efforts.
Join Dagster and Neurospace to learn:
- How to build AI pipelines with orchestration baked in
- How to track data lineage for audits and traceability
- Tips for designing compliant workflows under the EU AI Act
Register for the technical session
DuckDB: DuckLake - SQL as a Lakehouse Format
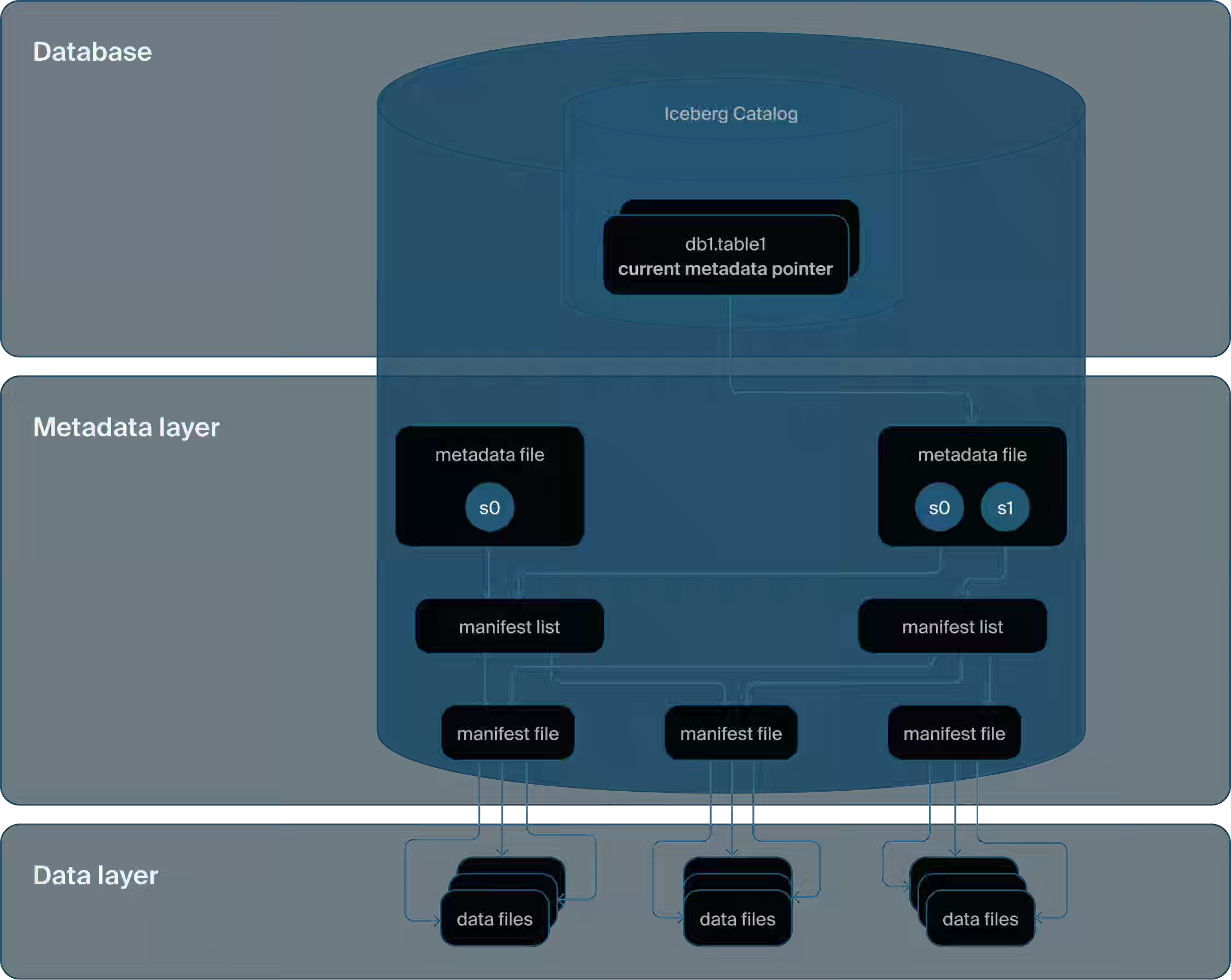
DuckDB announced a new open table format, DuckLake. This announcement has triggered many interesting conversations about storing metadata in a relational database vs. object storage. Is this what Hive metastore should be iterating from storing logical partition to time travel & built-in snapshot tables? With S3 Express One, why not metastore in Express One vs a relational database, which can reduce additional complexity? I don’t know which one gains industry adoption, but DuckLake brings some interesting questions into the ecosystem.
https://duckdb.org/2025/05/27/ducklake.html
Simon Späti: The Open Table Format Revolution - Why Hyperscalers Are Betting on Managed Iceberg
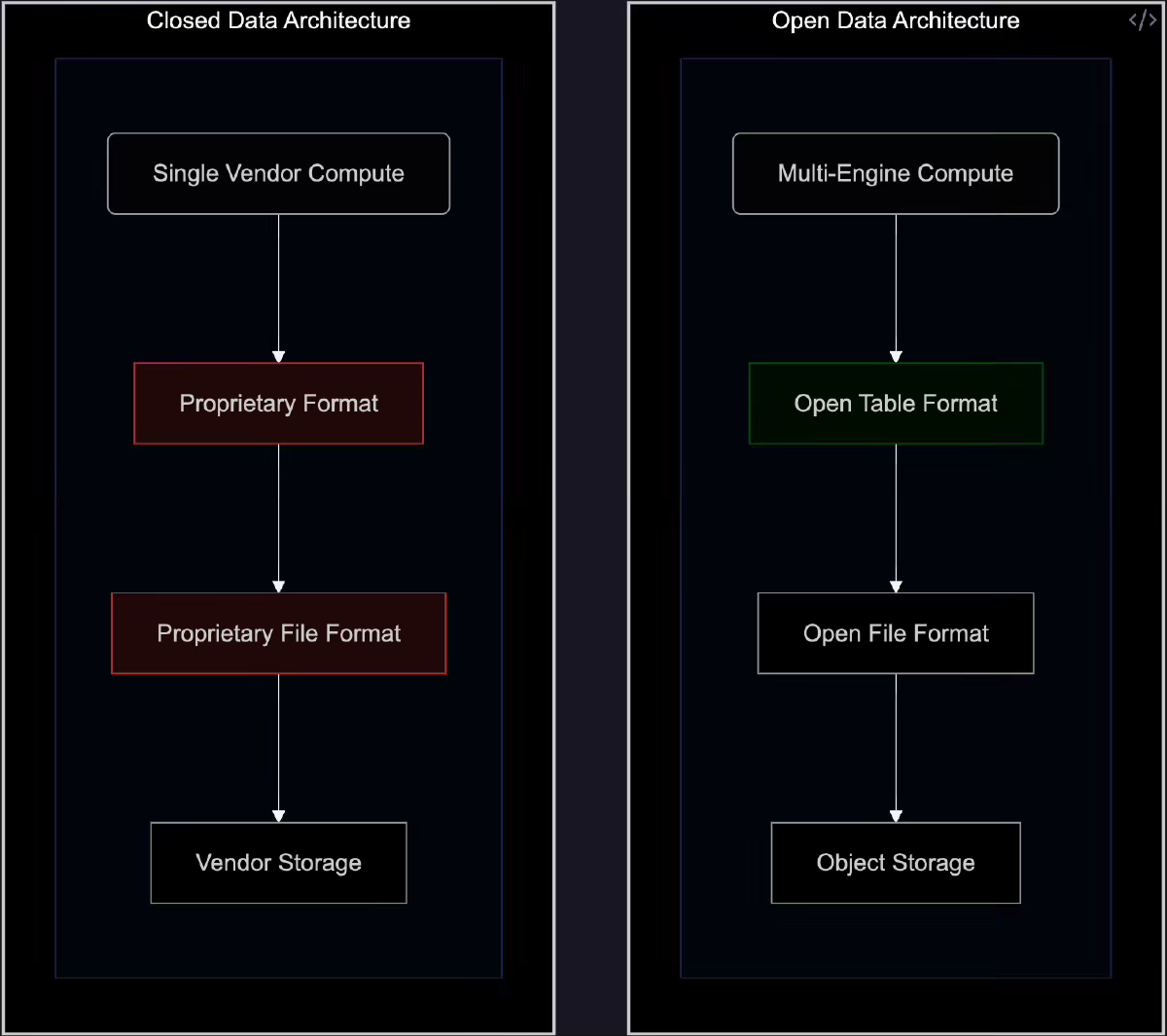
TIL about ICE (Interoperable, Composable, Efficient) stack. Data Engineering Weekly recently published a reference architecture for a composable data architecture. ICE stack elegantly represents the reference architecture. The author further highlights why hyperscalers like AWS, Azure, and Cloudflare offer managed Iceberg services.
https://www.ssp.sh/blog/open-table-format-revolution/
Stephen Diehl: Attention Wasn't All We Needed

Since the original Attention Is All You Need paper, many modern techniques have been developed. The author provides a comprehensive overview of all the latest techniques with a PyTorch code example.
https://www.stephendiehl.com/posts/post_transformers/
Sponsored: The Data Platform Fundamentals Guide

Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Instacart: How Instacart Built a Modern Search Infrastructure on Postgres
Postgres is becoming the one ring to rule them all. Instacart narrates its search infrastructure evolution from Elasticsearch to PGVector, including adopting FAISS for semantic search. I have concerns about mixing search infrastructure with a typical transactional workload. In the Instacart case, though they use Postgres, the instance seems isolated for search indexing rather than a hybrid transactional + search infrastructure.
Dropbox: How we brought multimedia search to Dropbox Dash
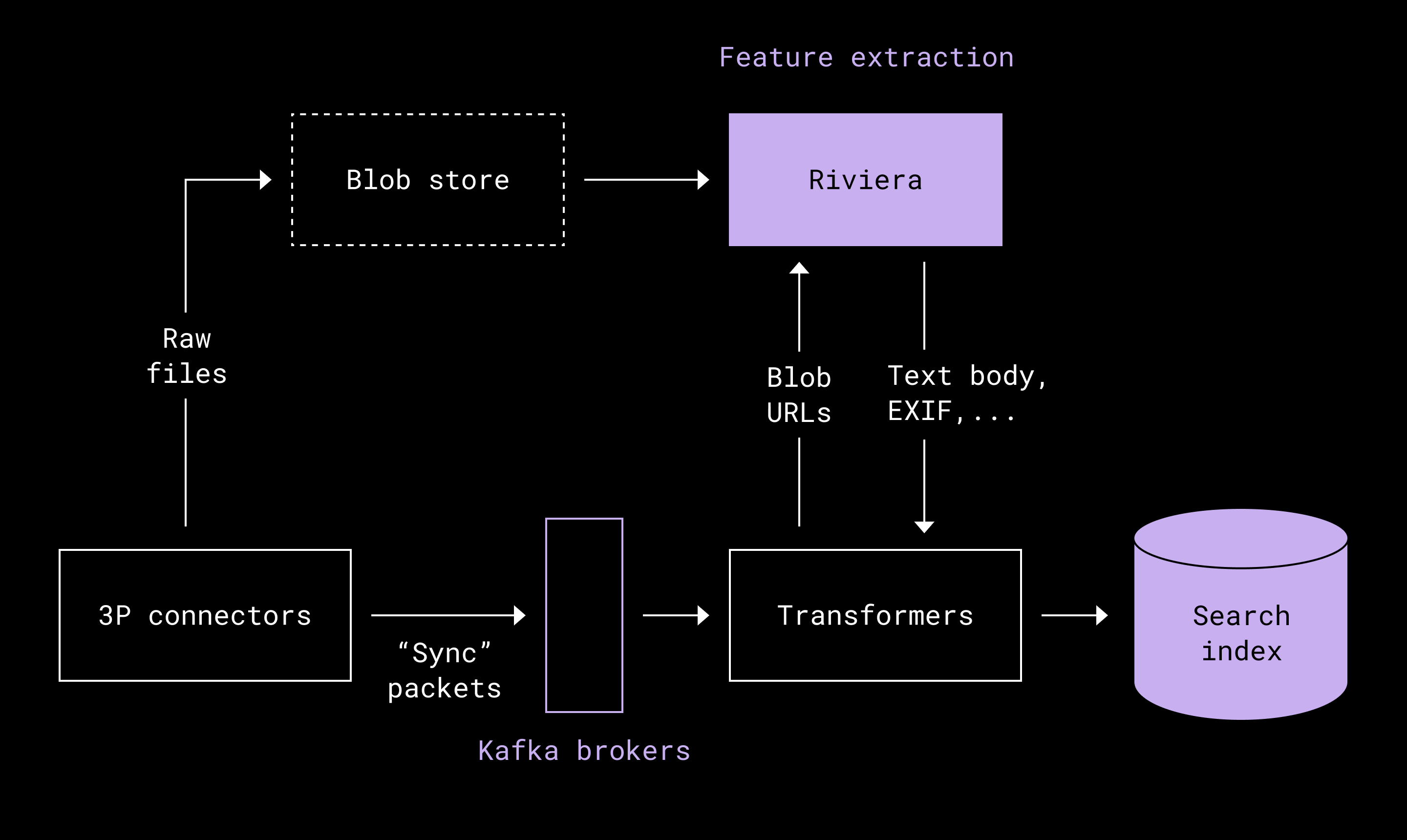
Searching in all data formats will be the next big push in data engineering, and that is one area I’m excited about. Dropbox shares the challenges in indexing multimedia files, its approach to solving the problem, and lessons learned.
https://dropbox.tech/infrastructure/multimedia-search-dropbox-dash-evolution
Uber: Enhanced Agentic-RAG - What If Chatbots Could Deliver Near-Human Precision?
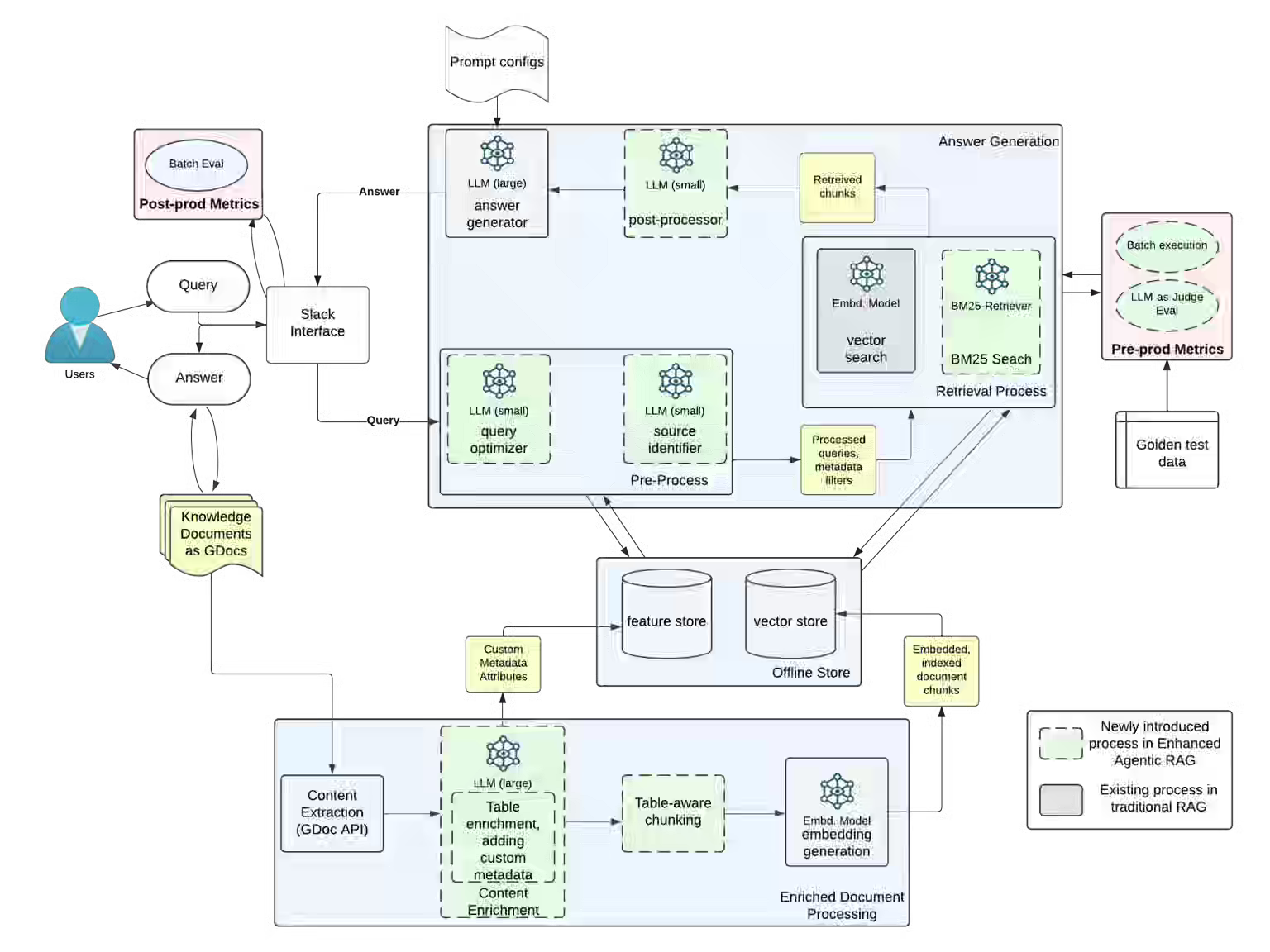
The “Tap the Shoulder problem” is one of the biggest productivity killers in the knowledge industry.
A quick question on Slack will inevitably summon your subject matter expertise. Uber writes about Genie, its internal Slack bot, and the effort to build Genie’s answer quality to near-human precision.
https://www.uber.com/blog/enhanced-agentic-rag/
Whatnot: 6x Faster ML Inference: Why Online≫Batch
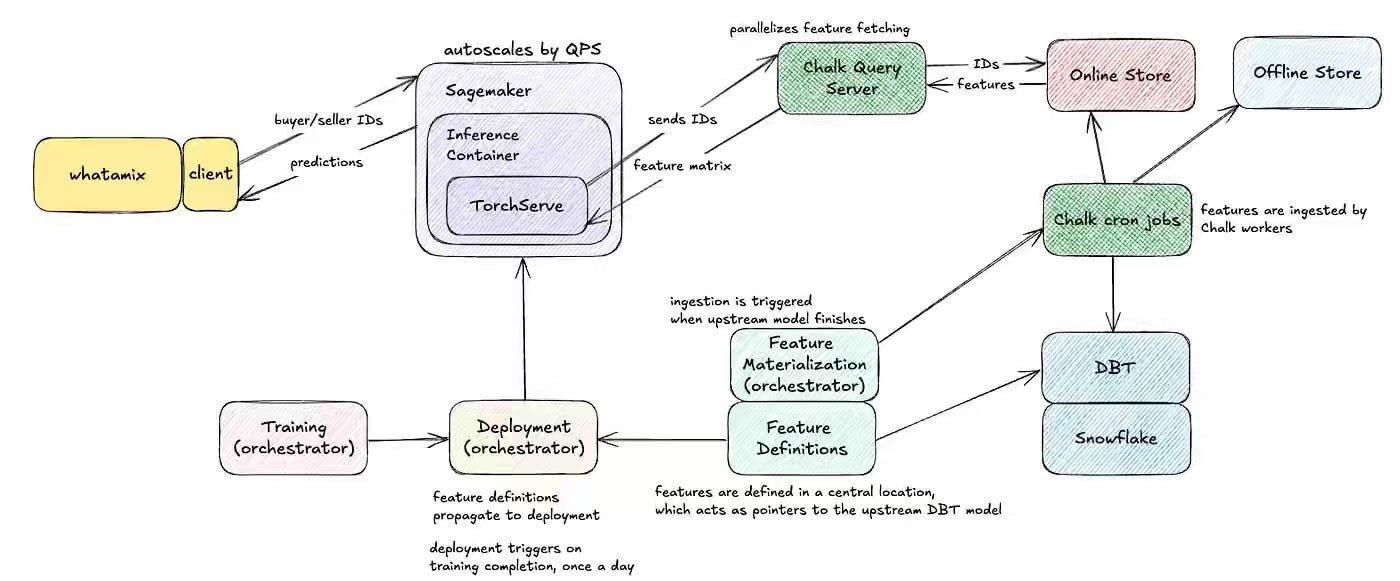
Whatnot writes about the challenges in scaling batch inference as the number of users grows, and the optimization to move towards online inference. The blog narrates adopting a hybrid approach with AWS Sagemaker integration and Chalk feature store.
https://medium.com/whatnot-engineering/6x-faster-ml-inference-why-online-batch-16cbf1203947
Pinterest: Modernizing Home Feed Pre-Ranking Stage
Pinterest describes modernizing its Home Feed pre-ranking stage, moving from a design where lightweight rankers ran separately on each retrieval source to a more unified system and model architecture. The new pre-ranking layer features a request-level sub-component (processing user/context features to generate a compressed user representation) and an item-level sub-component (performing online item feature extraction, processing, and user-item feature crossing), which are jointly trained but decoupled for efficient serving using a root-leaf architecture to manage a large item corpus.
https://medium.com/pinterest-engineering/modernizing-home-feed-pre-ranking-stage-e636c9cdc36b
Airbnb: Listening, Learning, and Helping at Scale - How Machine Learning Transforms Airbnb’s Voice Support Experience
Airbnb writes about enhancing its Interactive Voice Response (IVR) system using machine learning to improve voice-based customer support. The system reimagined IVR journey involves automated speech recognition (ASR) fine-tuned with Airbnb-specific terminology (reducing word error rate from 33% to ~10%), a Contact Reason Detection model to classify caller intent, a Help Article Retrieval and Ranking system (using semantic retrieval and LLM-based re-ranking) to provide relevant self-service information via SMS/app notifications, and a paraphrasing model (using curated summaries and nearest-neighbor matching) to summarize user intent before delivering solutions.
EloElo: Building EloElo’s Data Platform - Our 2-year Journey to Batch + Real-Time Lakehouse on Open Source stack
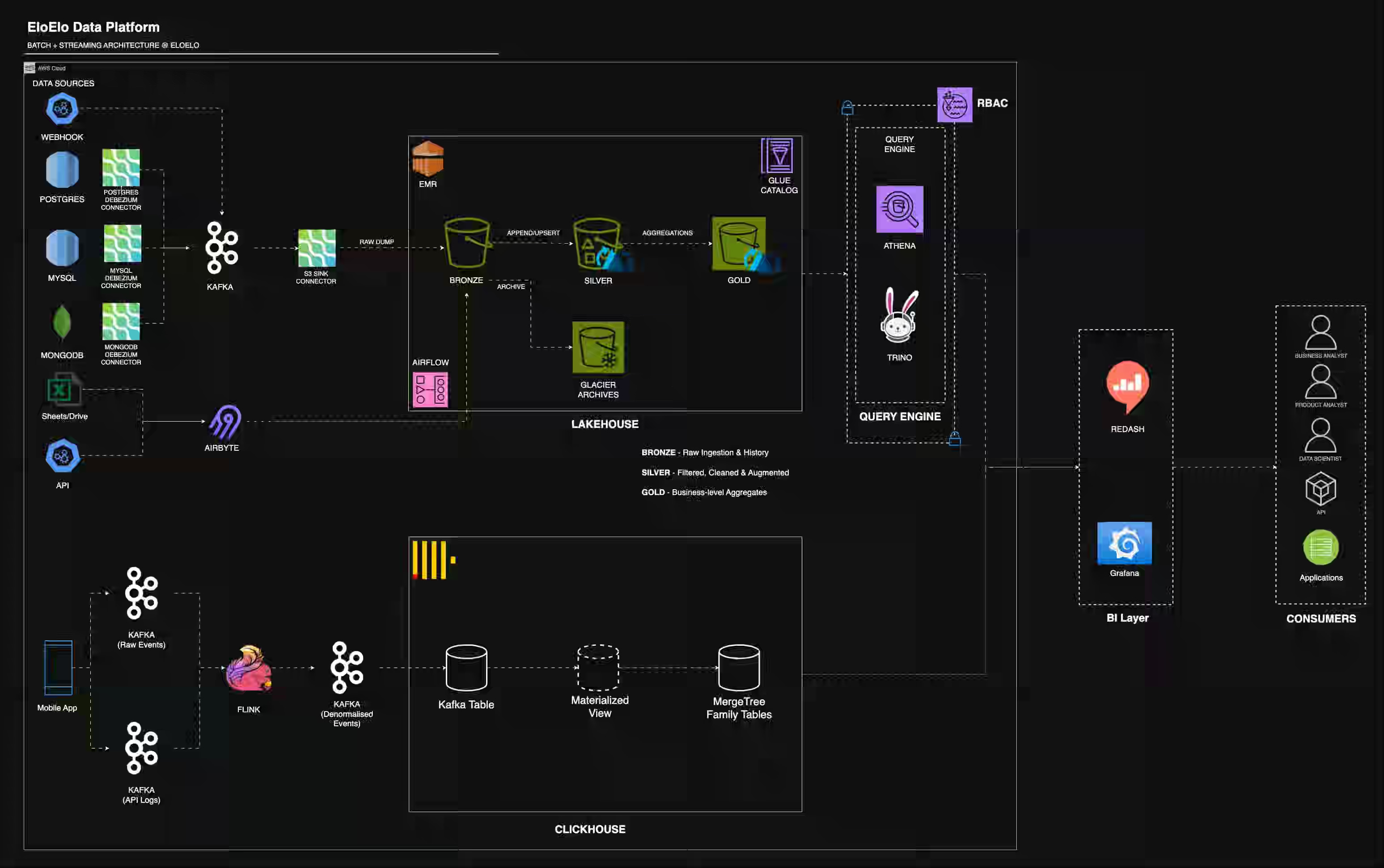
The blog captures the emerging lakehouse architecture, combining CDC pipelines and event sourcing systems. The architecture highlights one industry challenge: We still need a specialized OLAP engine like Clickhouse for real-time query capabilities and the typical data ingestion flowing to Lakehouses. The OLAP engines tend to store the data in their proprietary format, so though they provide tiered architecture and cold storage, running a duplicate pipeline and data duplication are inevitable.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.