
Data Engineering Weekly #238
The Weekly Data Engineering Newsletter


Dagster Components are now generally available.
Dagster Components deliver configurable, reusable pipeline building blocks that let you declare assets, resources, schedules, and more with almost no boilerplate. Instead of writing lengthy Python code for every asset or job, you can now define them in a few lines of YAML or lightweight Python.
Check out our full release blog with resources to get you started building your own Components.
Richard Artoul: The Case for an Iceberg-Native Database: Why Spark Jobs and Zero-Copy Kafka Won’t Cut It

As the adoption of Iceberg increases, fundamental design limitations are emerging in several ingestion flows. I wrote about handling fast changing dimensions in Iceberg last week. The author writes why zero-copy design with Iceberg Makes Existing Tiered Storage Implementations Worse.
Dr. Thea Klaeboe Aarrestad: Big Data and AI at the CERN LHC
A must-watch for any data practitioners to think about data engineering at scale. The talk highlights the practical limitations of collecting data, the architectural design for identifying and collecting critical data, and the attention to detail required to instrument the events.
Stripe: How we built it - Real-time analytics for Stripe Billing
Businesses need real-time visibility into subscription metrics to adapt pricing strategies quickly, but traditional batch systems create delays and limit flexibility. Stripe writes about its billing analytics pipeline with Apache Flink for streaming state management, Spark for historical backfills, and Apache Pinot’s new v2 engine for windowed aggregations. The architecture delivers sub-15-minute latency (microbatch rather than real-time?) and sub-300ms query times.
https://stripe.com/blog/how-we-built-it-real-time-analytics-for-stripe-billing
Sponsored: The data platform playbook everyone's using

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how to it will help you solve problems more quickly
Sanjeev Mohan: Is Your Data “AI-Ready”? Why Good Data Isn’t Enough Anymore
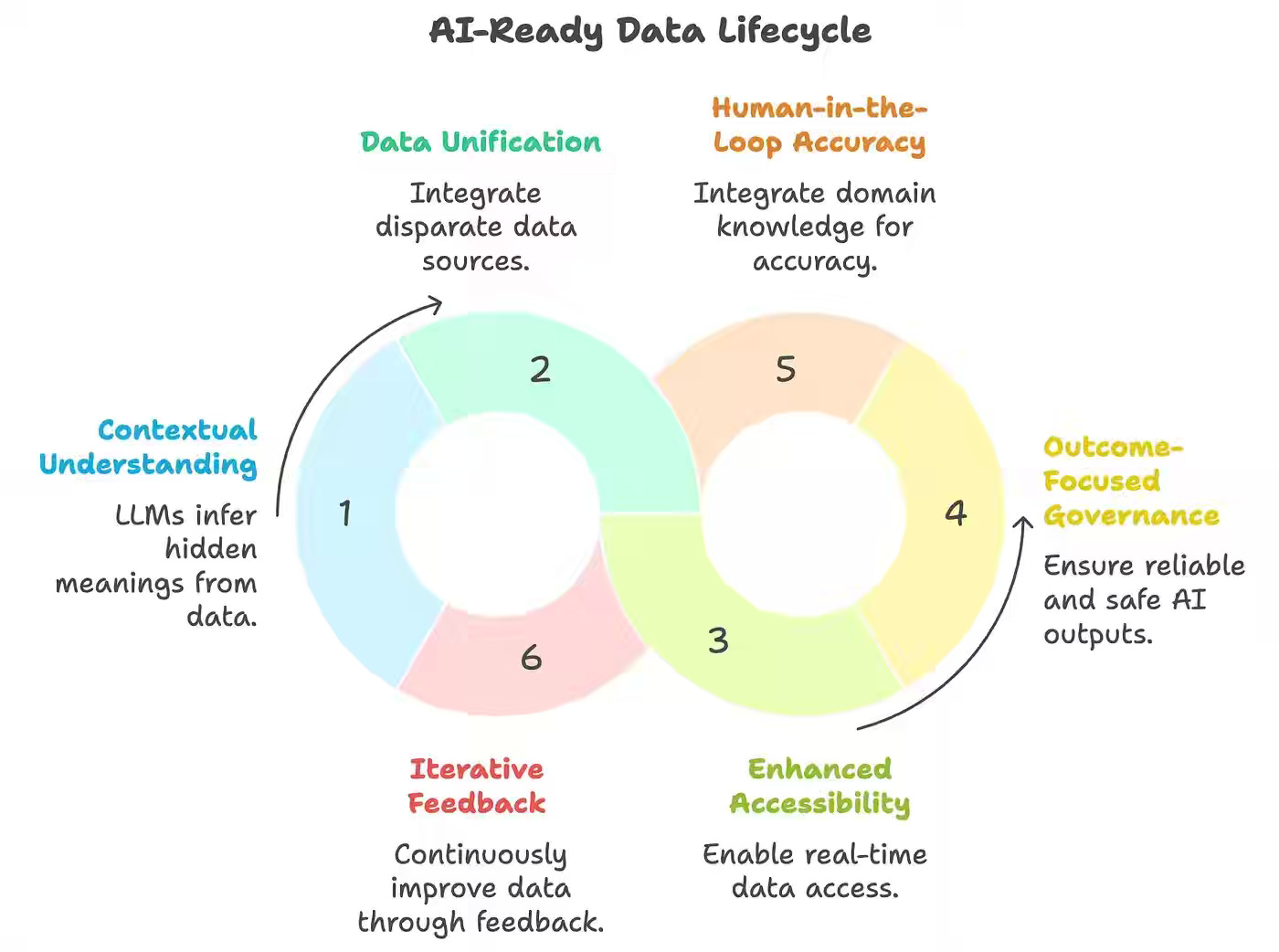
Enterprises racing to adopt AI often underestimate that the biggest barrier isn’t the model but the data feeding it. This author argues that “AI-ready” data goes beyond traditional quality and governance, requiring six pillars: contextual understanding, unified across silos, real-time accessibility via data fabrics, outcome-focused governance, human-in-the-loop accuracy, and iterative feedback loops. Without these capabilities, organizations risk confident but dangerously wrong AI outputs, while with them they can build reliable, explainable, and scalable AI systems.
https://sanjmo.medium.com/is-your-data-ai-ready-why-good-data-isnt-enough-anymore-e4d49baba52f
BlaBlaCar: Scaling Success - The dbt Ecosystem at BlaBlaCar
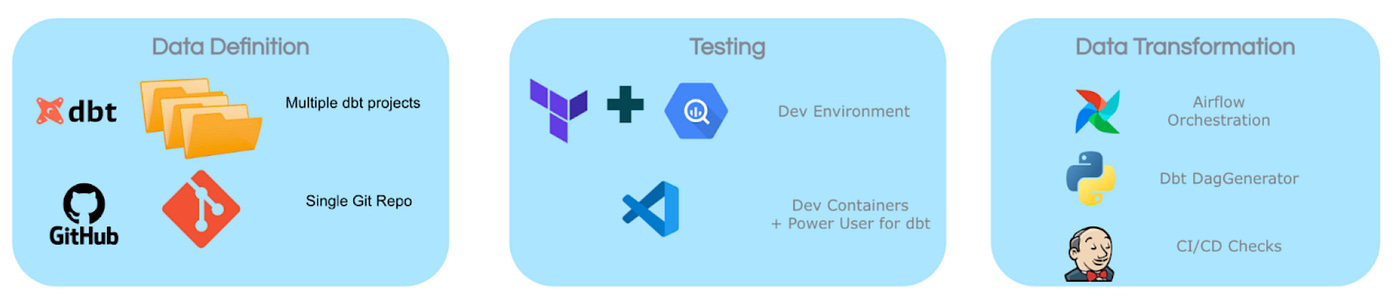
BlaBlaCar writes about managing thousands of tables and reports across multiple marketplaces. The blog talks about how it built a comprehensive dbt ecosystem—anchored by dbt Core, Airflow orchestration, custom tools like dbtDagGenerator, Dev Containers, isolated BigQuery dev environments, and CI/CD checks—to streamline developer experience, enforce standards, and ensure production stability.
https://medium.com/blablacar/scaling-success-the-dbt-ecosystem-at-blablacar-c214c4b8f0cb
Sponsored: Join the industry’s first survey on data platform migrations.

Most data teams have faced code or logic migrations—rewriting SQL, translating stored procedures, or replatforming ETL workloads—and they’re rarely straightforward. But there’s no clear benchmark for how long these projects take, what they cost, or how teams actually validate success.
Datafold is running a 5-minute survey to collect ground truth from practitioners on timelines, validation, budgets, and how AI is introducing new ways of tackling code translation and validation. Qualified Data Engineering Weekly subscribers get a $25 gift card, and all participants receive early access to the results.
Take the survey.
Anton Borisov: How Tables Grew a Brain: Iceberg, Hudi, Delta, Paimon, DuckLake
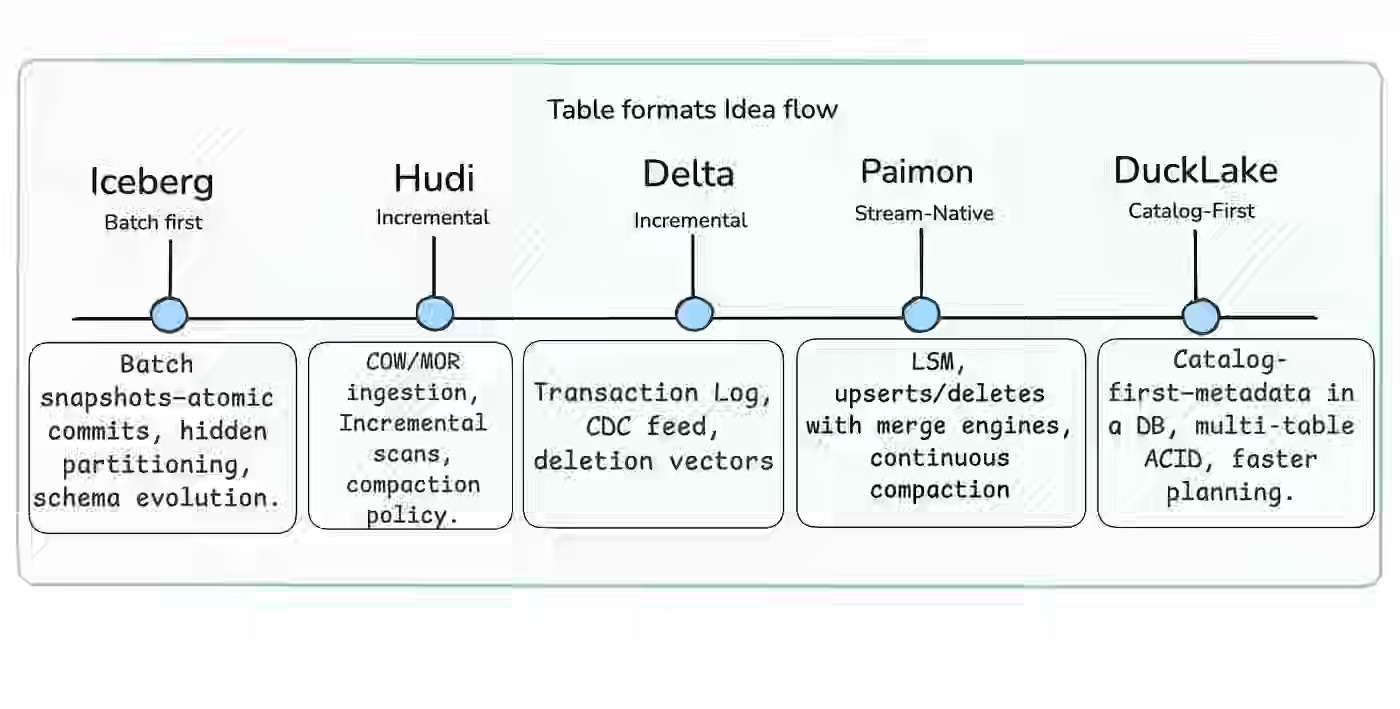
Open Lakehouse formats are accelerating enterprise adoption, but data teams struggle to choose and operate lakehouse tables as their needs shift from batch snapshots to continuous upserts and multi-table consistency, with metadata increasingly becoming the bottleneck. The author traces the idea flow—Iceberg’s snapshot reads, Hudi/Delta’s incremental COW/MOR and txn logs, Paimon’s stream-native LSM, and a catalog-first “DuckLake” that puts metadata in a transactional database—and offers a pick-by-intent playbook.
UiPath: How UiPath Built a Scalable Real-Time ETL Pipeline on Databricks
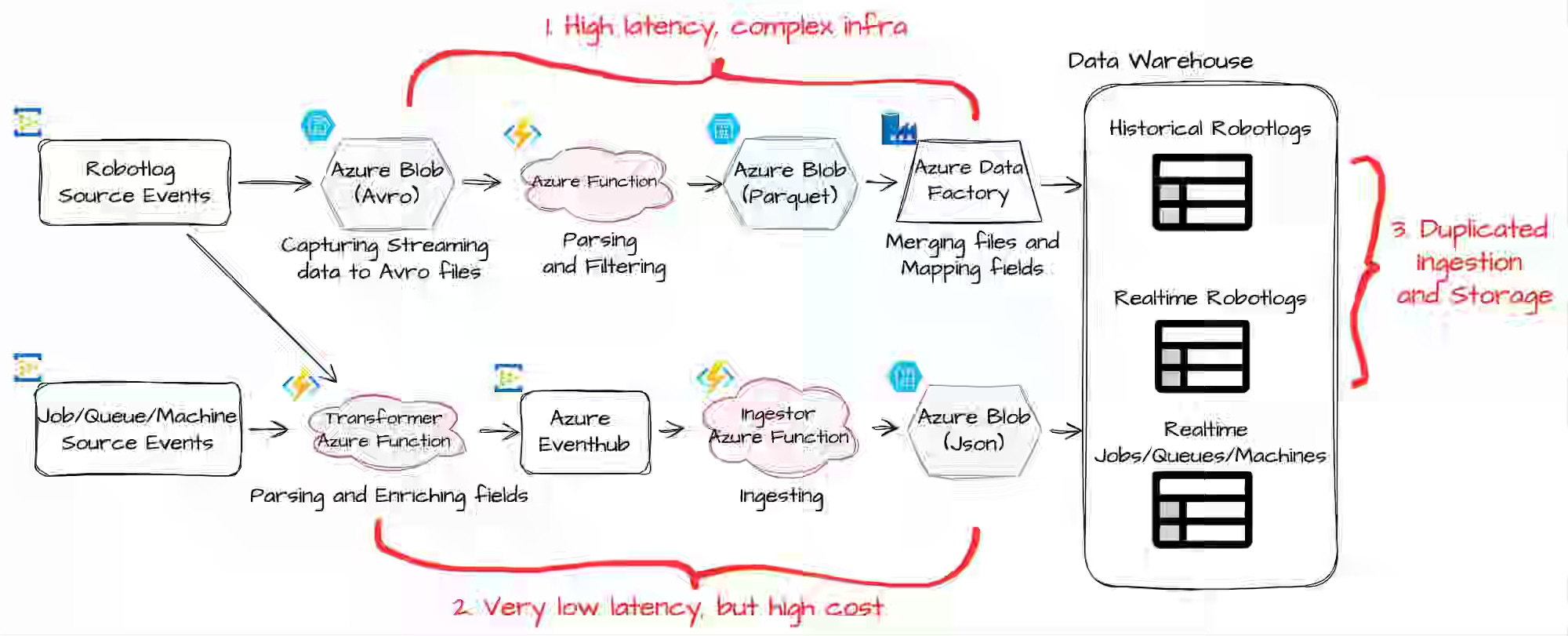
Enterprises building real-time AI and automation products frequently encounter scaling and latency issues when managing separate batch and streaming pipelines. UiPath writes about how it re-architected the data foundation on Azure Databricks with Spark Structured Streaming, unifying ingestion paths, consolidating Robotlogs processing, and leveraging Databricks Lakeflow Jobs for orchestration, checkpointing, and recovery.
Chris Riccomini: This MCP Server Could Have Been a JSON File
Many in AI are excited about Model Context Protocol (MCP) as a way for LLMs to discover and use external tools. The author questions MCP as it mostly a reinvents existing standards like OpenAPI, gRPC, and CLIs, offering little that’s truly new. While MCP defines resources, tools, and prompts, in practice, these resemble static documentation and RPC definitions that could easily be expressed in OpenAPI or CLI form.
https://materializedview.io/p/mcp-server-could-have-been-json-file
Kelsey Kinzer: The Ultimate Guide to LLM Evaluation: Metrics, Methods & Best Practices
Teams shipping LLM features struggle to measure quality in non-deterministic, open-ended workflows where “correctness” is contextual and can drift over time. The guide lays out a system-level evaluation playbook—blend human review, automated metrics, and LLM-as-judge methods (including RAG-specific checks) tied to clear dimensions like faithfulness, relevance, safety, and cost—then operationalize it with tracing, curated datasets, targeted metrics, repeatable experiments, and continuous production monitoring.
https://www.comet.com/site/blog/llm-evaluation-guide/
Weston Pace: Columnar File Readers in Depth: Structural Encoding
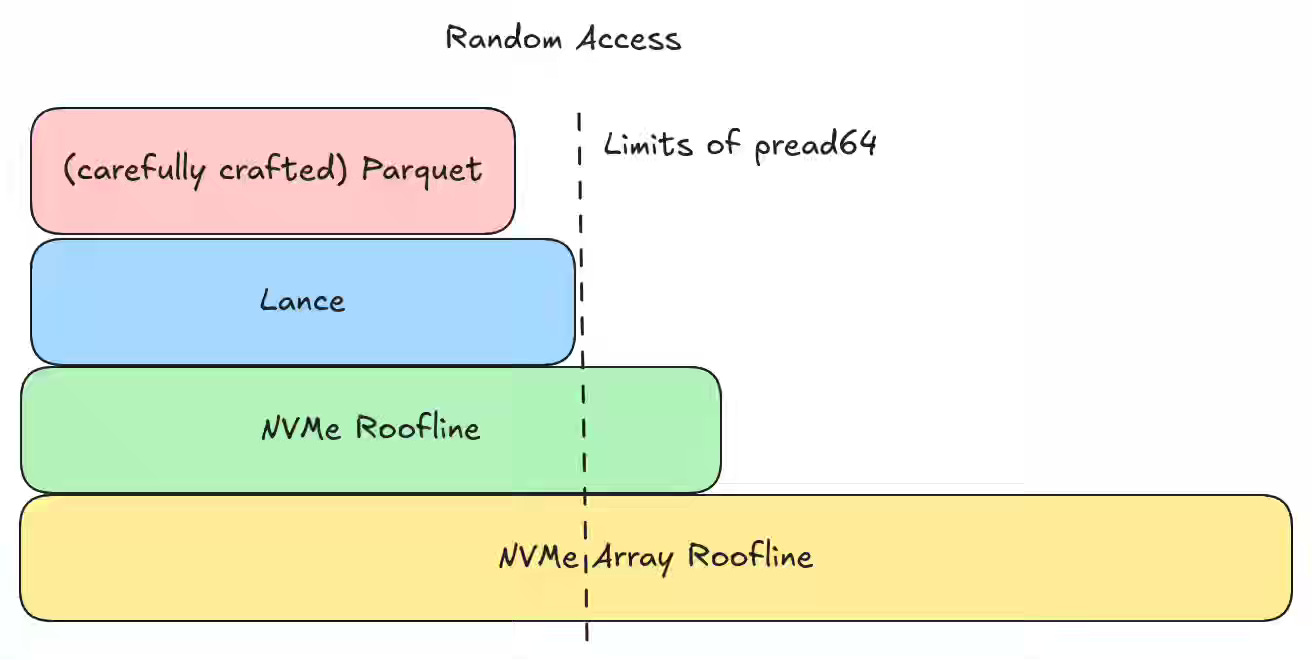
Columnar lakehouse readers struggle to balance fast random access for single values with high-throughput scans, especially when compression, I/O patterns, and multimodal (large) values pull in opposite directions. LanceDB’s post explains two structural encodings it uses—mini-block (small types, tolerate a little read amplification to maximize opaque compression) and full-zip (large types, transparent compression + zipped buffers for true per-value reads)—each with a repetition index for random access, and contrasts them with Parquet/ORC/Arrow IPC trade-offs.
https://lancedb.com/blog/columnar-file-readers-in-depth-structural-encoding/
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.