
Data Engineering Weekly #257
The Weekly Data Engineering Newsletter


Dagster Running Dagster
In this upcoming session, find out how Dagster's data team has increased its capacity, along with best practices for data modeling that work well with AI assistants. We'll also demo a real case where our Compass Dagster+ integration identified the root cause of a Postgres-to-Snowflake pipeline that was failing 40-50% of the time.
Ben Lorica: Your agents need runbooks, not bigger context windows
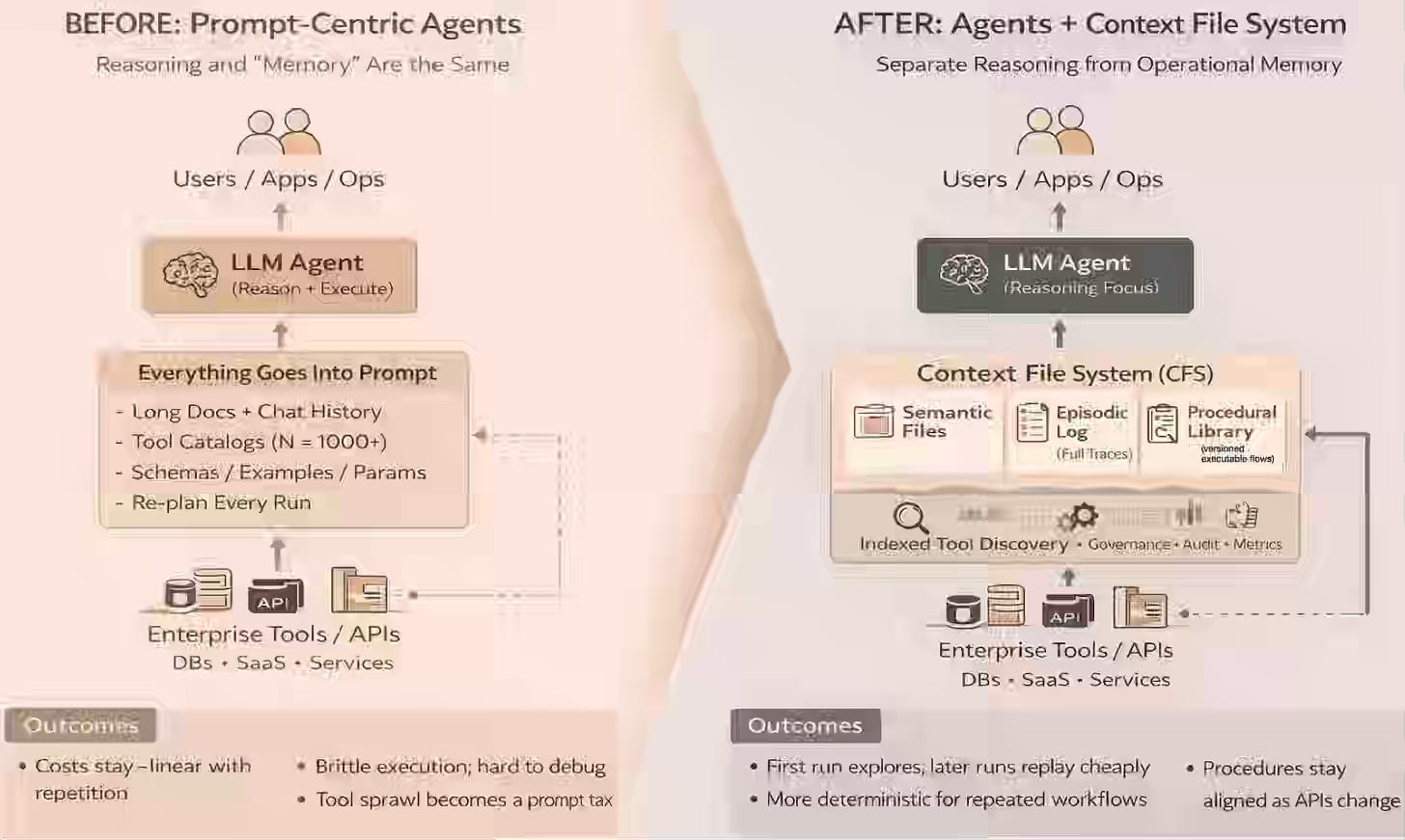
AI agents struggle to scale in operational environments because they rely on large, transient context windows that reset after each task and incur repeated planning costs. The article discusses a Context File System (CFS) that separates reasoning from persistent procedural memory, enabling agents to mount task-specific runbooks, reuse indexed tools, and replay proven workflows.
https://gradientflow.substack.com/p/the-missing-layer-in-todays-agent
Netflix: High-Throughput Graph Abstraction at Netflix - Part I
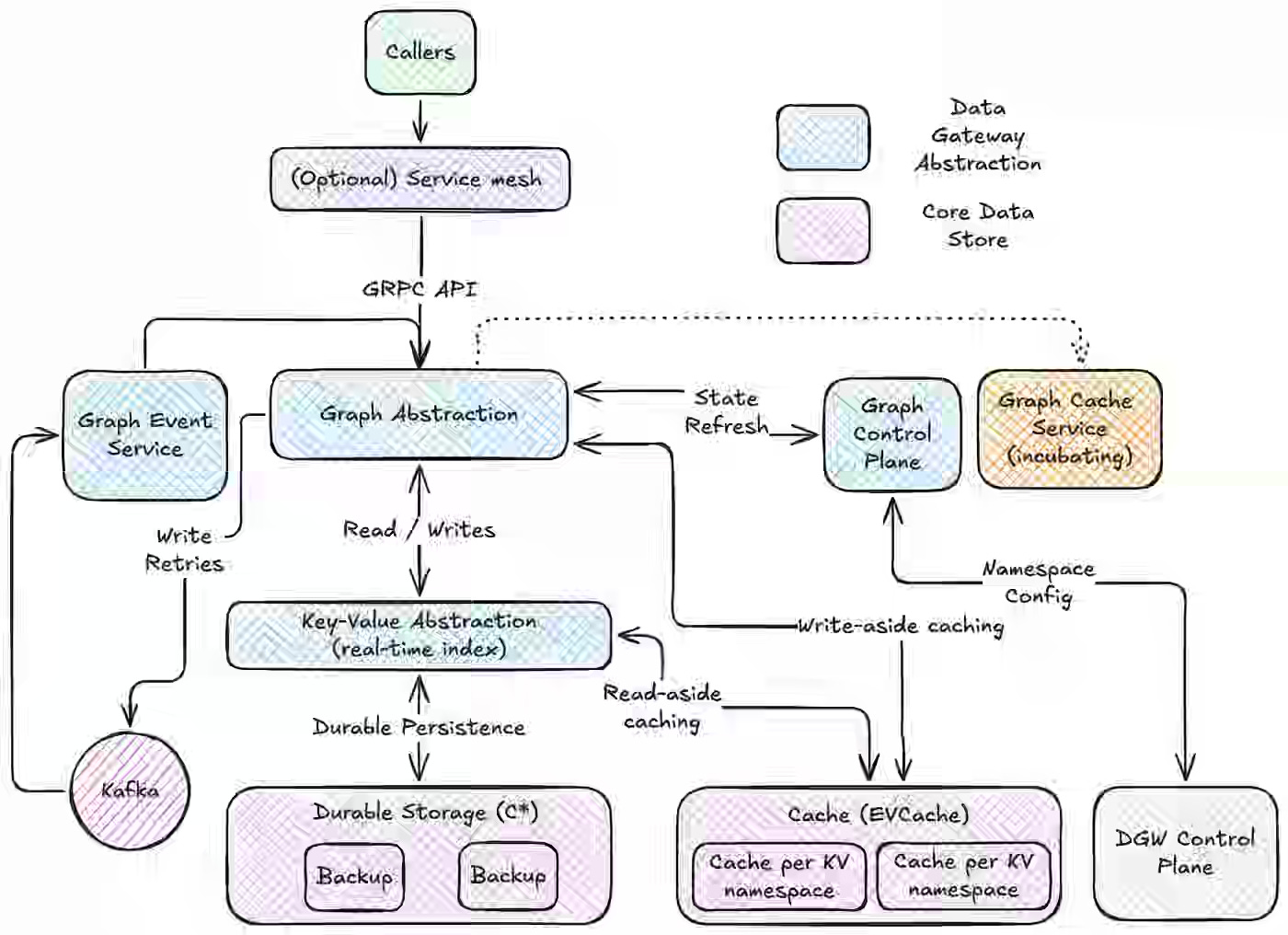
High-throughput OLTP graph workloads demand low-latency traversal, strong typing, and global consistency at scale. The article explains how Netflix built a Graph Abstraction service on existing KV, TimeSeries, and caching infrastructure, using a property graph model with partitioned namespaces, optimized edge indexing, and write- and read-aside caching. The architecture processes millions of operations per second with single-digit millisecond latency while maintaining strict eventual consistency across regions.
https://netflixtechblog.medium.com/high-throughput-graph-abstraction-at-netflix-part-i-e88063e6f6d5
Reliable Data Engineering: Data Contracts in Practice - What 50 Production Implementations Actually Look Like

I recently wrote about Data Contract - a missed opportunity, the recent Twitter conversation, and the recent OSI spec from Snowflake reflecting the traces of Data Contract. The author did a solid job summarizing various data contract patterns and their implementations.
Sponsored: The AI Modernization Guide

Learn how to build a data platform that enables AI-driven development, reduces pipeline failures, and cuts complexity.
- Transform from Big Complexity to AI-ready architecture
- Real metrics from organizations achieving 50% cost reductions
- Introduction to Components: YAML-first pipelines that AI can build
Netflix: Scaling LLM Post-Training at Netflix
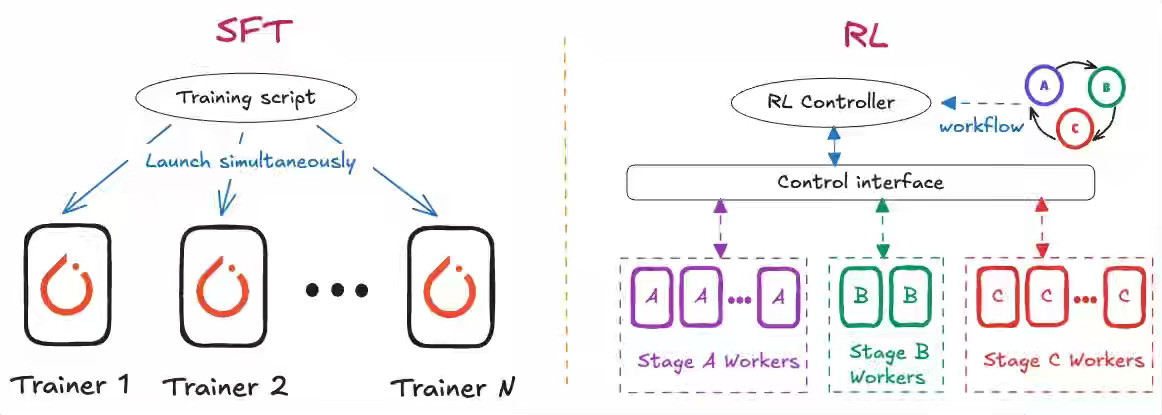
Production LLM deployment requires a scalable post-training infrastructure that handles complex data pipelines, distributed GPUs, and evolving fine-tuning strategies. The article explains how Netflix built a unified post-training framework on its ML platform to support efficient SFT and RL workflows, modular data and model abstractions, and tight integration with open-source ecosystems. Custom optimizations, such as sequence packing and hybrid RL orchestration, increase token throughput and enable researchers to focus on modeling rather than infrastructure.
https://netflixtechblog.com/scaling-llm-post-training-at-netflix-0046f8790194
Abhishek Goswami: From Prompts to Production: A Playbook for Agentic Development
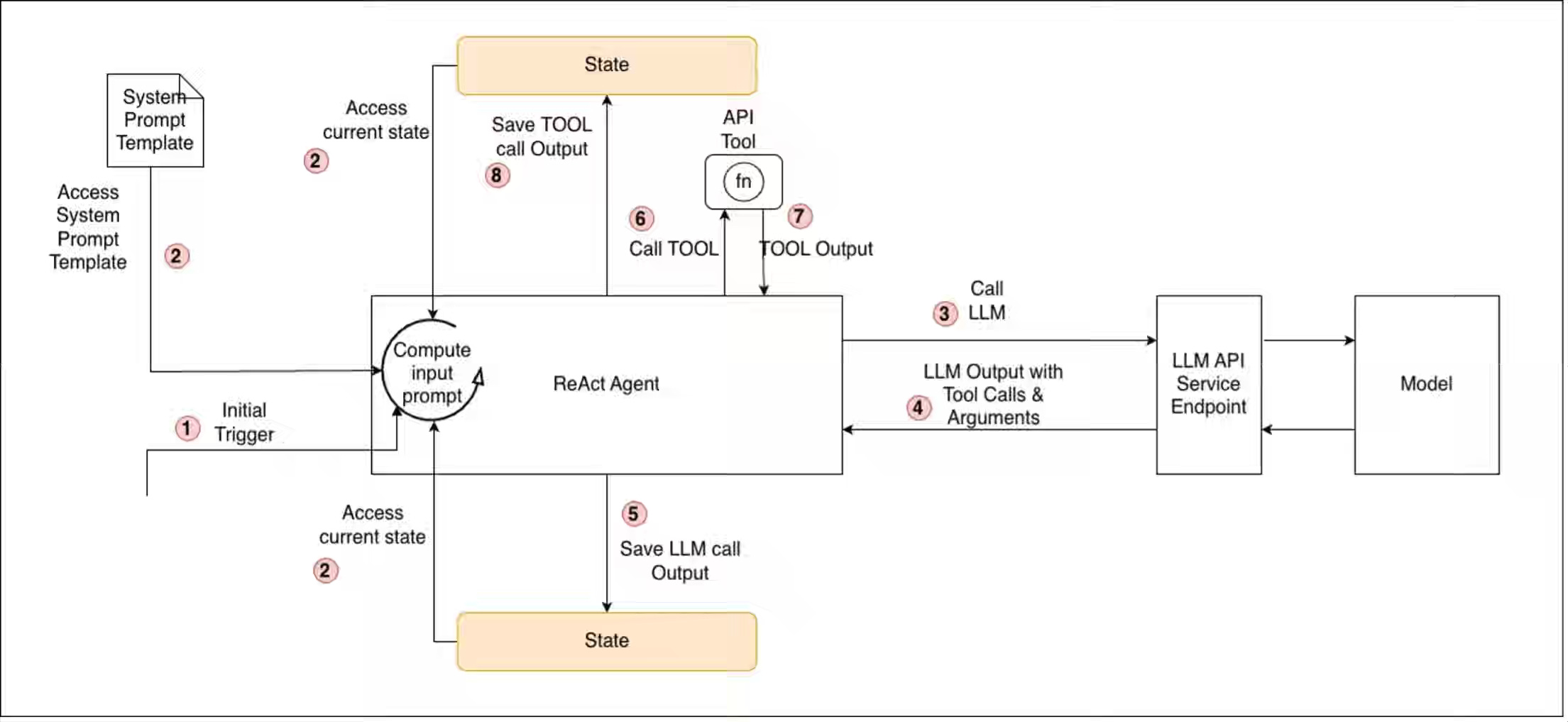
Enterprise AI agents fail in production when teams rely on prompt experimentation without structured lifecycle and behavioral controls. The article introduces an Agentic SDLC that separates deterministic and agentic components, applies reusable orchestration patterns, and enforces versioned prompts, tool manifests, and MCP-based integrations. Behavioral testing with golden trajectories, layered validation, and human-in-the-loop oversight enables reliable, scalable deployment of agents beyond prototypes.
https://www.infoq.com/articles/prompts-to-production-playbook-for-agentic-development/
Zepto: How We Built High-Precision, Low-Latency Semantic Search in Production
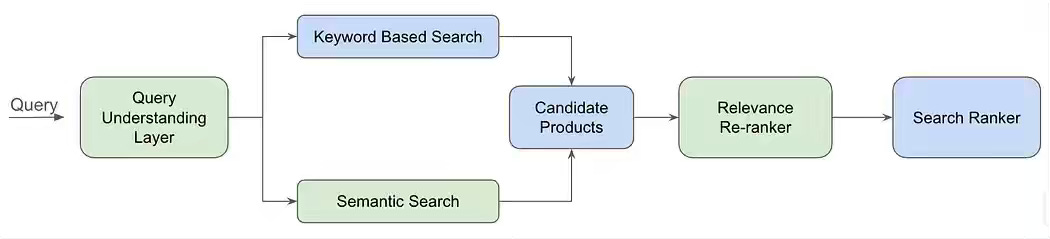
Keyword-based search fails on short, misspelled, and tail queries that lack lexical overlap with product catalogs. The article explains how Zepto built a dual-encoder semantic retrieval system trained with weak supervision, synthetic data, and InfoNCE loss to learn intent-aware embeddings under strict latency constraints. The approach delivered a 35% uplift on impacted queries, improved downstream ranking quality, and enabled semantic retrieval for both search and ads use cases.
Atlas9: The challenges of soft delete
Deleting data is one of the hardest problems; it is easy to write, but hard to delete. The standard approach is soft deletion, and it has several complications. The article covers the nuances of soft deletes, architectural patterns, and best practices for handling delete system design at scale.
https://atlas9.dev/blog/soft-delete.html
Apache Parquet: Native Geospatial Types in Apache Parquet
It is exciting to see Apache Parquet evolve with the addition of more types and indexing support. The flexibility of a data format that allows you to select data types and the indexing patterns associated with them improves data management efficiency. I wish Apache Parquet/Lakehouse formats such as Hudi, Iceberg, and Delta Lake offered the flexibility of Apache Pinot’s types and indexing patterns.
https://parquet.apache.org/blog/2026/02/13/native-geospatial-types-in-apache-parquet/
Dalto Curvelano: Introduction to PostgreSQL Indexes
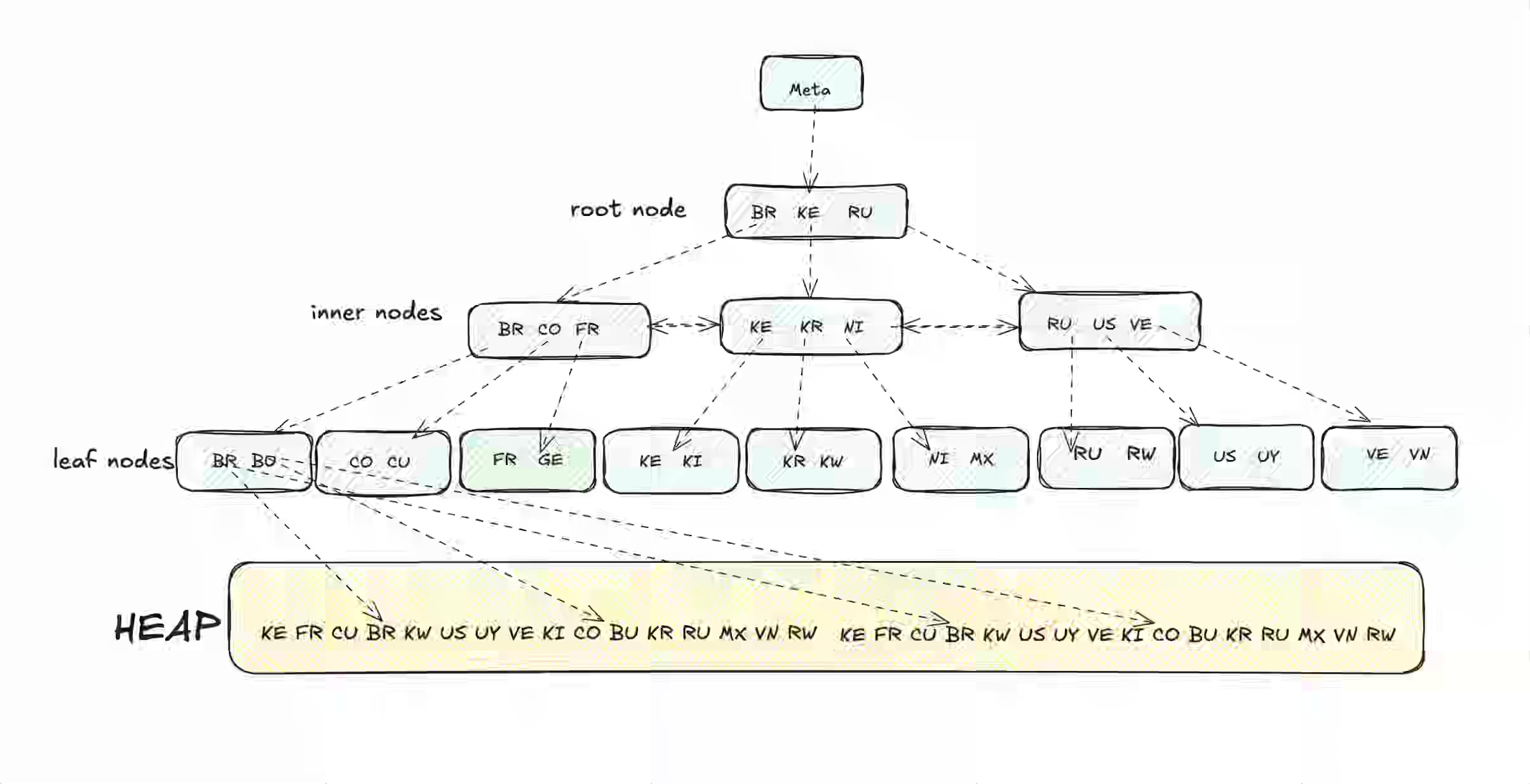
Speaking of types and indexing, it always comes back to basics and a solid foundation. The article is an excellent overview of PostgreSQL indexing support and its use.
https://dlt.github.io/blog/posts/introduction-to-postgresql-indexes/
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.