
Data Engineering Weekly #263
The Weekly Data Engineering Newsletter


How data teams are solving multi-tenancy
As data teams grow and serve multiple teams, clients, or business units from a shared platform, maintaining isolation and velocity without sacrificing either becomes a defining architectural challenge.
In this Deep Dive, Dagster Labs and Brooklyn Data Co. will cover the patterns, trade-offs, and real-world implementations behind multi-tenant data platforms built on Dagster. Attendees will leave this session with practical guidance they can take back to their own teams.
Aurimas Griciūnas: State of Context Engineering in 2026
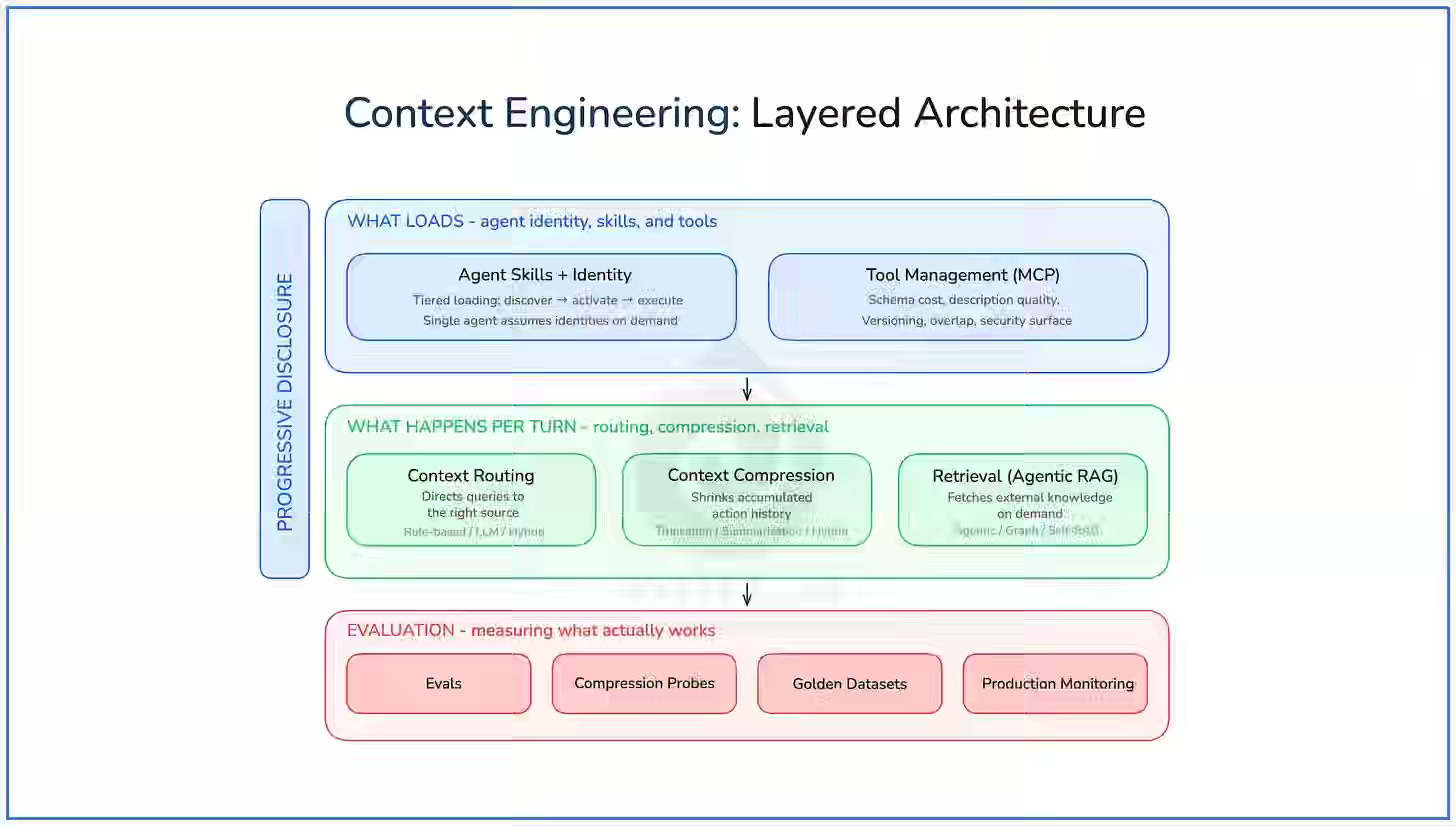
LLM reasoning degrades with oversized context, forcing developers to manage attention through structured context engineering rather than scaling model size. The author outlines five patterns—progressive disclosure, compression, routing, agentic RAG, and tool management—that control how context is selected and applied. Layered orchestration across discovery, activation, and execution enables complex agent behavior within fixed context limits while preserving reasoning quality.
https://www.newsletter.swirlai.com/p/state-of-context-engineering-in-2026
Joe Reis: AI Is Here, But The Hard Parts Haven’t Changed
AI is accelerating coding velocity, but it’s also exposing structural weaknesses that data teams have ignored for years—legacy systems, misaligned leadership, and poor business context modeling. Data from Joe Reis’s March 2026 survey reinforces the gap: teams are shipping code faster, yet many still lack clarity on production value, while data modeling and semantic layers are emerging as the next critical frontier. Data engineering now faces a reset moment—improving end-to-end delivery efficiency matters more than optimizing isolated pipelines, a direction I’ve been exploring in “Data Engineering After AI” and “ETL is Dead.”
https://joereis.substack.com/p/ai-is-here-but-the-hard-parts-havent
Hamel Husain: The Revenge of the Data Scientist
LLM API accessibility enables rapid AI feature development but obscures reliability requirements grounded in evaluation and experimental design. The author argues modern AI development reuses core data science practices: analyzing production traces, validating LLM-as-judge with precision and recall, grounding test sets in real data, and using domain experts to define criteria. Teams that avoid synthetic benchmarks and over-automation focus on inspecting data to identify failure modes, reinforcing the role of data scientists as reliability gatekeepers.
https://hamel.dev/blog/posts/revenge/
Sponsored: The Data Platform Fundamentals Guide

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Figma: Redefining impact as a data scientist
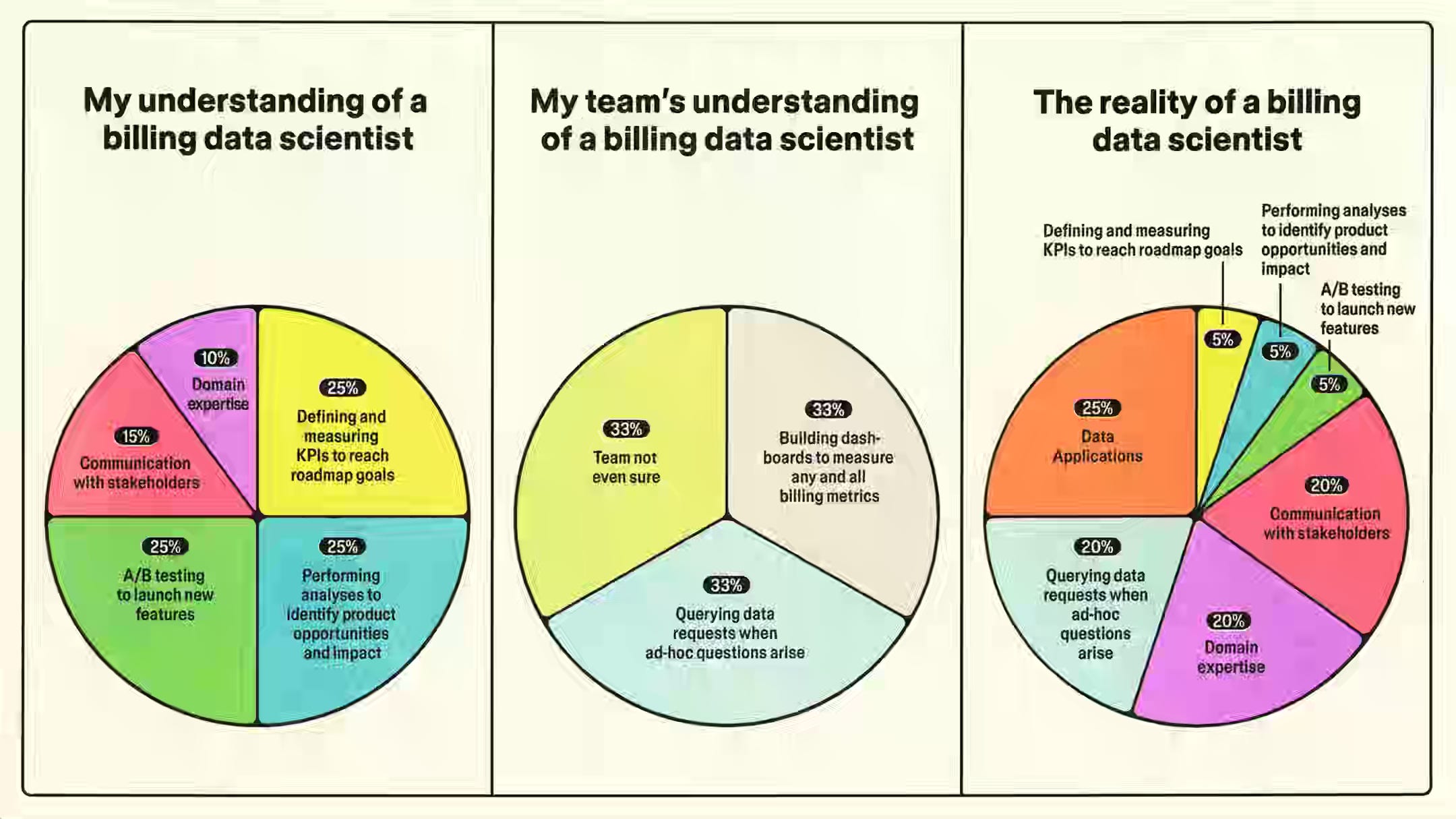
Data science impact in mission-critical systems like billing depends on domain expertise and observability rather than experimentation, shifting focus from models to correctness and clarity. The author describes Figma’s full-stack approach, where data scientists build consistency checks, create applications that explain system behavior, and define correctness criteria. Embedding these practices into operational systems scales their impact through tools rather than reports.
https://www.figma.com/blog/redefining-impact-as-a-data-scientist/
BlaBlaCar: Beyond the dashboard: how BlaBlaCar PMs use AI to self-serve data
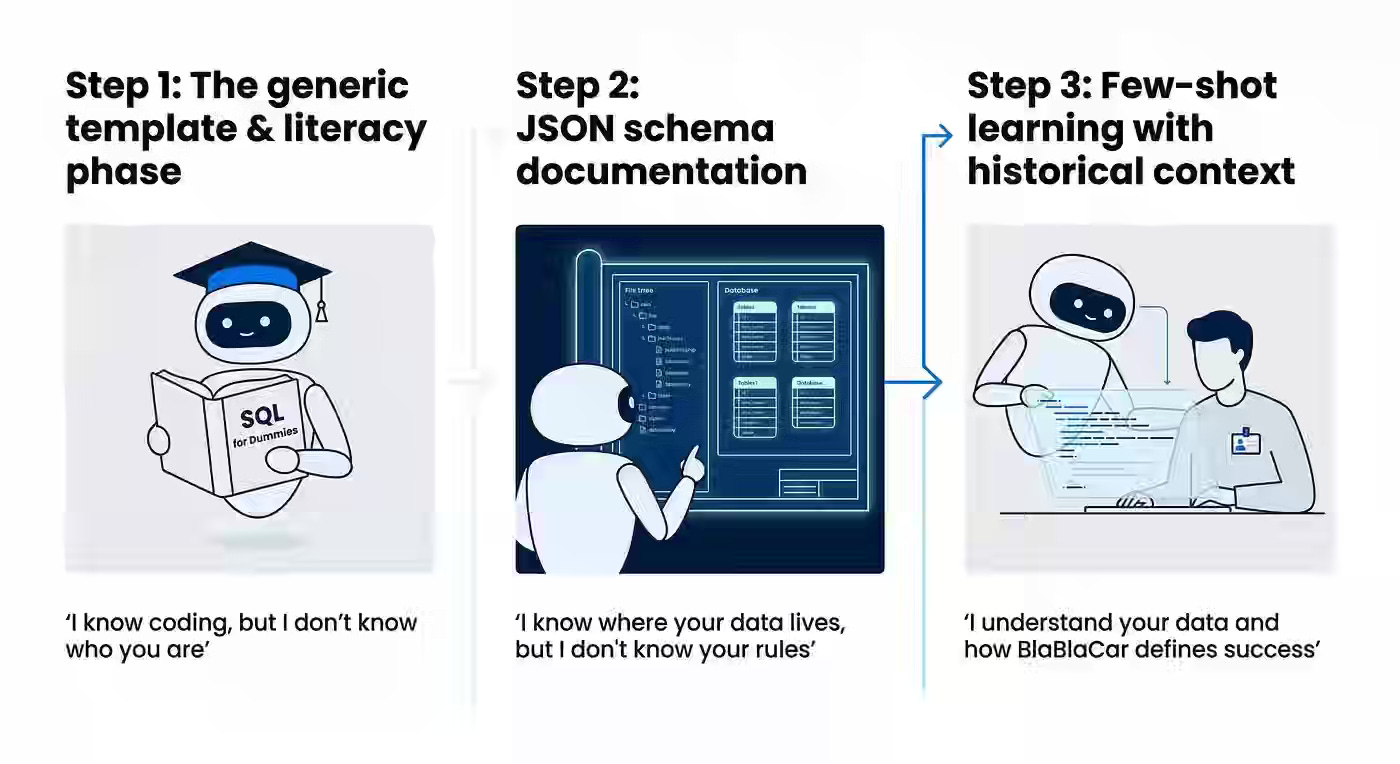
Data analyst bottlenecks in fast-moving organizations require enabling non-technical users to self-serve without compromising data integrity or introducing hallucinations. BlaBlaCar evolves its approach from generic LLM usage to structured JSON schema documentation and few-shot learning on expert query histories, teaching the system to map natural language to business rules. A three-zone autonomy framework—safe, risky, and dead zones—combined with SQL literacy training for PMs reduces error rates from 32% to 15% and shifts analysts from reactive ticket handling to strategic work.
Expedia: Operating Trino at Scale With Trino Gateway
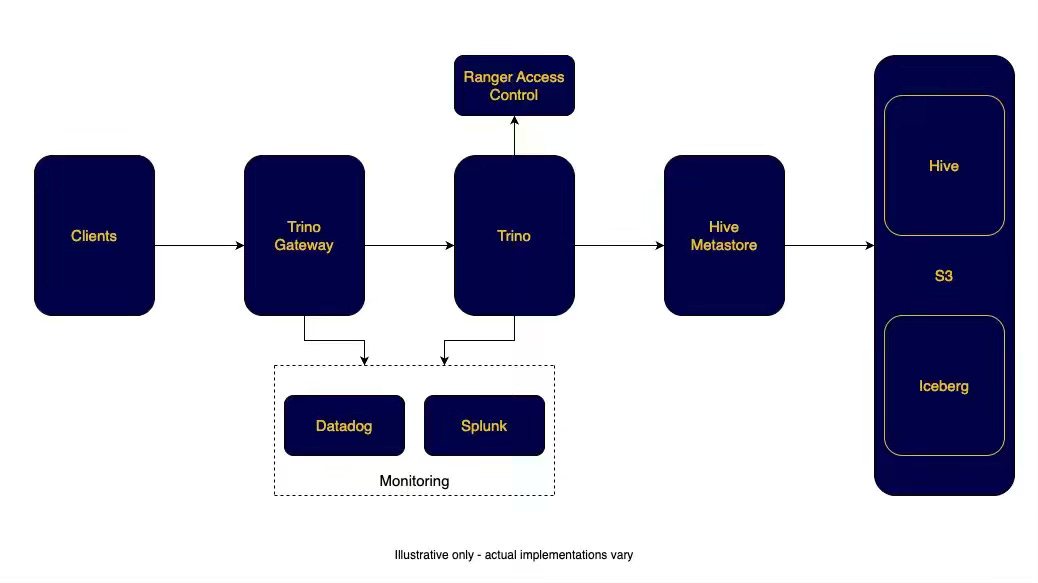
Managing Trino at scale requires isolating workloads to prevent resource contention across analytical, ETL, and BI queries. Expedia writes about operating Trino Gateway—a fork of Lyft's Presto Gateway—as a single-endpoint proxy that routes queries to dedicated clusters using configurable rules. This design eliminates noisy-neighbor failures, supports zero-downtime deployments, and provides real-time visibility into cluster health.
https://medium.com/expedia-group-tech/operating-trino-at-scale-with-trino-gateway-41824af788de
LangChain: How we build evals for Deep Agents
Building reliable AI agents requires evals that target specific production behaviors rather than optimizing for aggregate benchmark scores. LangChain's Deep Agents harness defines behavior-first evals sourced from production errors, BFCL, and hand-written unit tests — then scores agents on correctness and Ideal Trajectory ratios for step and tool-call efficiency. Teams run tagged eval subsets via pytest in GitHub Actions and trace every run in LangSmith to isolate failure modes and control evaluation cost.
https://blog.langchain.com/how-we-build-evals-for-deep-agents/
LinkedIn: The LinkedIn Generative AI Application Tech Stack: Personalization with Cognitive Memory Agent
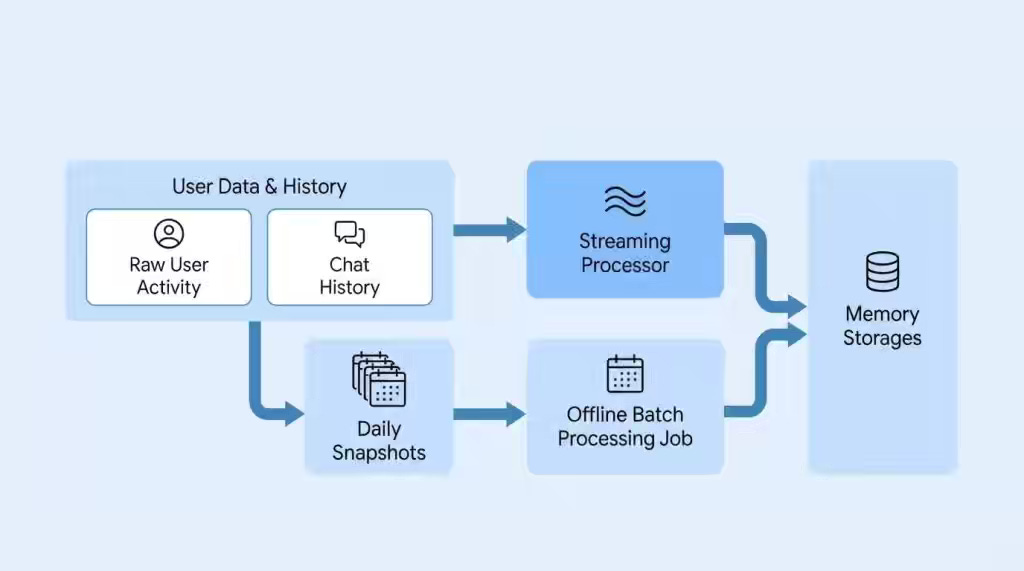
AI agents lose personalization across sessions because they lack structured memory that separates conversational, episodic, semantic, and procedural signals. LinkedIn’s Cognitive Memory Agent ingests activity traces through streaming and batch pipelines, then uses an LLM-based orchestrator to retrieve and reason across all four memory layers. This architecture enables the Hiring Assistant to auto-populate role requirements and generate recruiter-specific insights from historical hiring activity.
Ilia Gusev: Change Data Capture: Stop Copying 50M Rows to Move 5K Changes
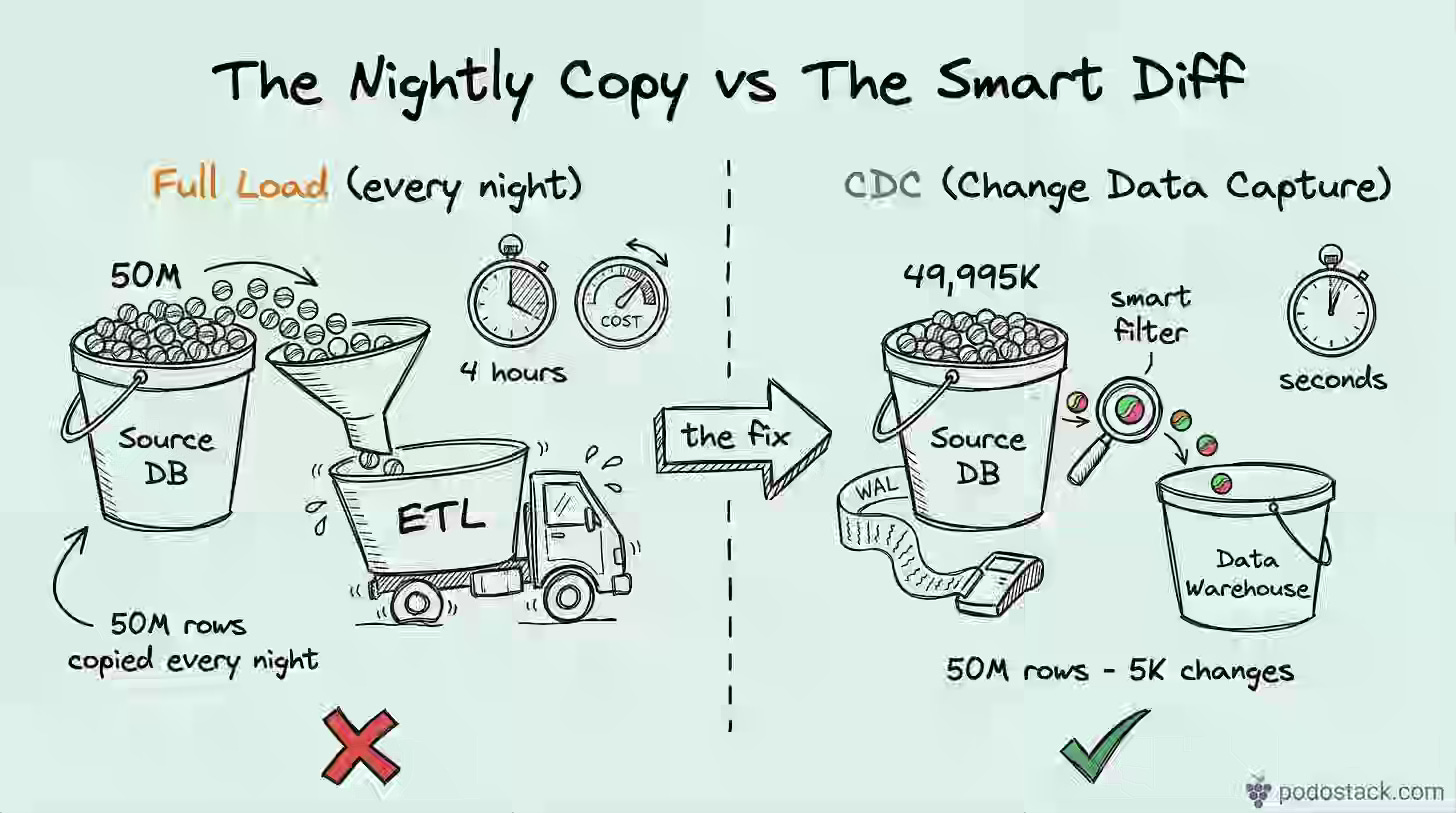
Nightly full-table copies introduce fragility and place increasing load on source databases as data volumes scale. The article contrasts timestamp, trigger, and log-based CDC approaches, recommending Debezium with Postgres WAL or MySQL binlog as the production standard for near-real-time replication without impacting OLTP performance. Log-based CDC captures hard deletes, handles DDL changes, and decouples replication throughput from transactional write load.
https://podostack.com/p/change-data-capture-cdc-intro
Micheal Lanham: The Markdown File That Beat a $50M Vector Database
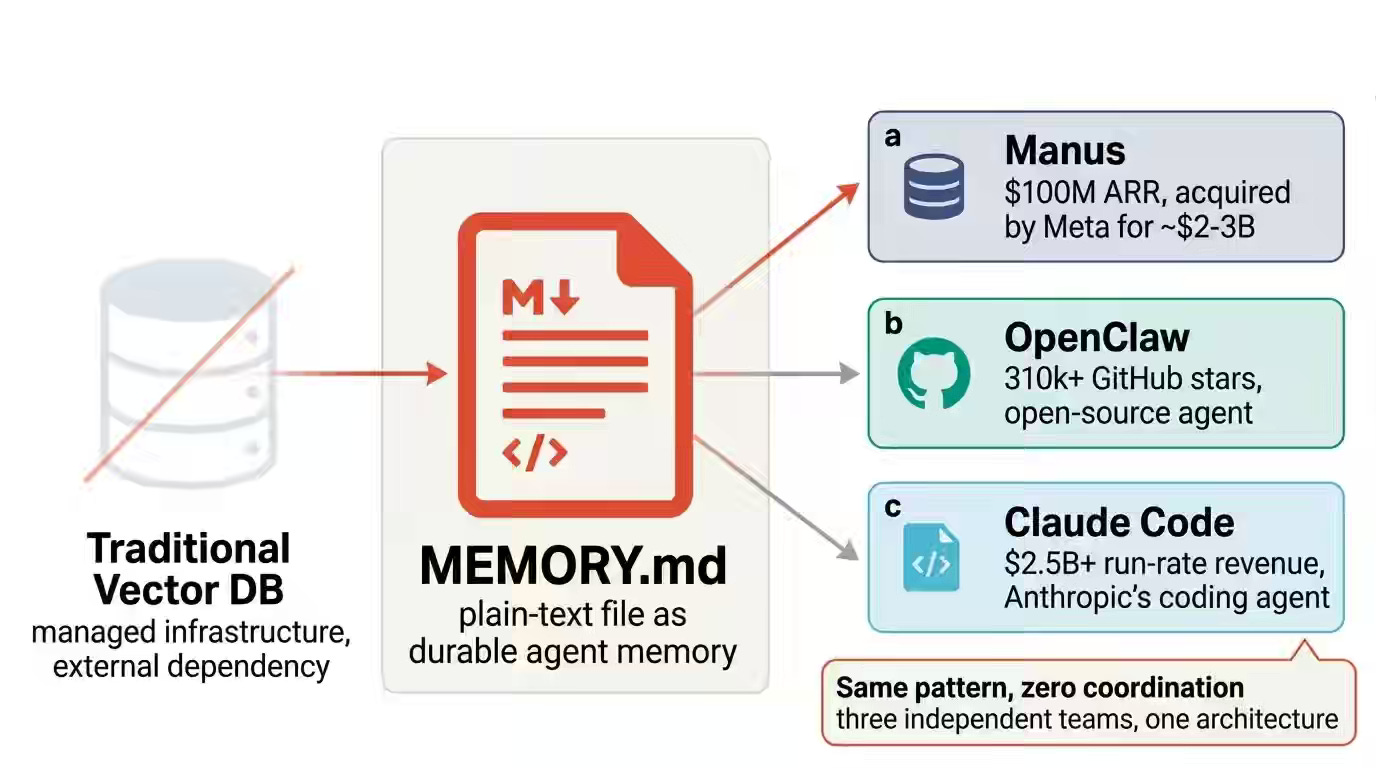
Agentic workflows expose the cost and operational overhead of managed vector databases when used for single-threaded memory and state management. The author shows how Manus, OpenClaw, and Claude Code converge on Markdown files as the primary memory layer, leveraging KV-cache efficiency, filesystem hierarchy for scoped retrieval, and sqlite-vec for lightweight semantic search. This file-first architecture reduces token costs by nearly 10x and defers vector database adoption to scenarios that require multi-user concurrency.
https://medium.com/@Micheal-Lanham/the-markdown-file-that-beat-a-50m-vector-database-38e1f5113cbe
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.